��ˣ�������܇��Ӕ�(sh��)�ֻ��a(ch��n)Ʒ���о�����ȫ������ȡܛ���o��늵�������Ҫ˼�룺��һ��Ҫʹ��܇��Ӯa(ch��n)Ʒ�[ÓӲ���Y(ji��)��(g��u)�����`���ڶ��������Dz�ҪӲ������������܇��Ӯa(ch��n)Ʒ��ԓ�����_���Ժͼ����ԣ��_����ָ��ʹ�õ��_�š������a(ch��n)���_�ź͌����Ƶ��_�š����棬�ͻ���ܛ���o��늵�˼��̽ӑDSP��FPGA����܇����е���Ҫ���á�
����DSP��FPGA��܇���Z����̖̎��
��܇��Ӯa(ch��n)Ʒ�е��Z��̎����Ҫ�漰���Z���Ĕ�(sh��)�ֻ�̎�����Z������a���Z�s���Z���R�e��������^���T����܇��Ӯa(ch��n)Ʒ֮һ�����Z���R�eϵ�y(t��ng)���Z���R�eϵ�y(t��ng)���Н��ڵđ���ǰ�����������Ԓ���Z���������������x��V���l�������I�Z���b�e�ȡ����磬һ�N�����[ʽ�R�ɷ�ģ�ͣ�HMM�����c�vԒ�˟o�P(gu��n)��100�lָ���R�e�đ��ã����īI��֪�������WHMMģ�͵Ĵ�С���顣�M�а���ݔ���Z���ɘӵļ���/�_����MFCC��ȡ������Ӌ���Viterbi�ь����m�r̎������DSP���\����Ҫ��һ���10000�f�γ˼ӣ�MAC���\�㡣�����B�m(x��)�Z����̖���R�e���tҪ����õĔ�(sh��)����̖̎���ٶȺ���Ĵ惦���g��
�����Z���R�eϵ�y(t��ng)Ҫ�����M�Ќ��r̎���Ͳɘӣ���Ҫ�������\�㣬���������20%��Ӌ���YԴ��������1000�f��MAC�Z���R�e���ã���ô��Ҫ̎�����܉����5000�f��MAC����������ˣ���횲���DSP��FPGA����������΄ա�DSP��FPGA��̎���ٶȌ��Z����̖̎�푪��ϵ�y(t��ng)�ď��s�Ժ����������Q�������ã�����DSP��FPGA�Č��F(xi��n)�Ɍ��F(xi��n)�����m���������m���ȬF(xi��n)���Z��̎�����R�e���g(sh��)������Փ���v��DSP��FPGA̎���ٶ�Խ�죬��܇�Z��̎�����R�e�a(ch��n)Ʒ�đ������ܾ�Խ�á�
�S������������ӻ���DSP��FPGA��׃�ɲ�����һ�K������оƬ����׃���˘�(g��u)����(n��i)�ˡ��@ʹ���O(sh��)Ӌ�����x����m�ă�(n��i)�˺͌���߉���z�Y(ji��)����һ���γɌ���DSP��FPGA�������ԝM����̖̎������Ҫ��Ŀǰ��߀���F(xi��n)��DSP�˺�ASIC������������һ���оƬ����܇���ϵ�y(t��ng)ʹ��ͨ��DSP��FPGA�팍�F(xi��n)�Z���ϳɣ��m�e���a�����Z���ϳɡ��Z�s�c���a��DSP�������V���đ��ã�ʸ�����a�����ڌ��Z����̖���s�����ގ������ŵ��С�
]]>ADSP-21xx
�Y(ji��)��(g��u)���c
16-bit���cDSP
��8-bit���o�40-bit
ACC�����ڈ�(zh��)��ָ�����(sh��)ָ��
���ԗl����(zh��)��
��ַģʽ
������(sh��)��ַ���Ĵ���ֱ�ӌ�ַ���惦��ֱ�ӌ�ַ���Լ��Ĵ����g�ӌ�ַ������ADSP-219x��߀�мĴ����º��ġ������ġ�ֱ�Ӻ��g��ƫ�ƌ�ַģʽ����������о��Ѓ�(n��i)��ѭ�h(hu��n)Ӌ��(sh��)��ѭ�h(hu��n)�ї����Ķ����F(xi��n)���_�Nѭ�h(hu��n)��ÿ����ַ�l(f��)����֧���Ă�ѭ�h(hu��n)���_����ÿ��ѭ�h(hu��n)���_�����������Ĵ������Á����xѭ�h(hu��n)�ĽK�c���L�Ⱥ��L���ĵ�ַ��һ����ַ�l(f��)����֧��λ����?q��)�ַ��ADSP-219x֧��ʮ����ѭ�h(hu��n)���_����ͨ�^ʹ��һ����ַ�l(f��)����Ӱ�ӼĴ�����һ�M���Ĵ�����������ѭ�h(hu��n)���_���`���ԡ�
����ָ��
ADSP-219x�����Зl���؈�(zh��)�д����(sh��)ָ���do until������Խ��������L�ȵ�ָ�����У����Č�Ƕ��ѭ�h(hu��n)��ADSP-219x�t֧�ְˌ�Ƕ�ס�ADSP-21xx�Ƿ���ˮ�C�ͣ�����������D(zhu��n)�ƻ��ӳ����{(di��o)�Î���Ӱ푡�
�_�l(f��)֧��
ADI��˾��ܛ����Ӳ���_�l(f��)���߰���ԓ��˾��VisualDSP�����_�l(f��)�h(hu��n)�����ھ����������_�l(f��)����VisualDSP�ṩ����(y��u)����C���g�����R�������B�������{(di��o)ԇ���Ľӿڡ�ԓ��˾�ķ������m����ͨ�õĴ��ڿ�����PCI���Լ���̫�W(w��ng)���Cƽ�_����EZ-Kit Lite����һ���u��������ġ��������Rȫ��VisualDSP��
TigerSharc DSP
�Y(ji��)��(g��u)���c
16-bit���cDSP
VLIW�����Lָ���֣��Y(ji��)��(g��u)������һ���C�����ڃ�(n��i)��(zh��)���ėlָ��
ԓϵ��DSP����SIMD���Ηlָ�������(sh��)��(j��)��������
��һ��TigerSharc DSP������6 Mbit��RAM
��ַģʽ
������(sh��)��ַ��λ����?q��)�ַ���Kѭ�h(hu��n)���Ĵ���ֱ�ӌ�ַ�ͼĴ����g�ӌ�ַ����SIMD�惦����ݔ�C��ʹ��ȡ��(sh��)�ʹ惦ָ���ڃɂ��惦���K�̓ɂ�Ӌ���Ԫ֮�g����(sh��)��(j��)��ݔ��
����ָ��
ָ�ֱ��֧�ָ߾��Ⱥ͵;�����͔�(sh��)��(j��)֮�g���D(zhu��n)�Q�����چ����ڃ�(n��i)�����c��(sh��)�D(zhu��n)�Q�ɸ��c��(sh��)����16-bit��(sh��)�D(zhu��n)�Q��32-bit��(sh��)��TigerSharc�]��Ӳ��ģʽ����ָ�֧�����g(sh��)���ܣ��玧��̖�ĺͲ�����̖������(sh��)��С��(sh��)�\�㡣�@���������Z�Եľ��̡��ڸ��N��r�¶��ṩ��(y��u)�����ģʽ��
�_�l(f��)֧��
ADI��˾��ܛ����Ӳ���_�l(f��)���߰���ԓ��˾��VisualDSP�����_�l(f��)�h(hu��n)�����ھ����������_�l(f��)����VisualDSP�ṩ����(y��u)����C���g�����R�������B�������{(di��o)ԇ���Ľӿڡ�ԓ��˾�ķ������m����ͨ�õĴ��ڿ�����PCI���Լ���̫�W(w��ng)���Cƽ�_����EZ-Kit Lite����һ���u��������ġ��������Rȫ��VisualDSP��
SHARC DSP
�Y(ji��)��(g��u)���c
16-bit���cDSP
֧�ֶ��c���c�\��
�µ�SIMD�N�^�\�㣨Hammer-head operates��
������SRAM
��ַģʽ
������(sh��)��ַ��������ַ��λ����?q��)�ַ���Kѭ�h(hu��n)���Ĵ���ֱ�ӌ�ַ�ͼĴ����g�ӌ�ַ��������Ƭ��惦�����L������횲����g�ӌ�ַ����
����ָ��
SHARC�ṩλ������ƽ�����ĵ���(sh��)���l���ӳ����{(di��o)�á����_�N�Ηlָ��͉Kָ��ѭ�h(hu��n)�����c��(sh��)���c��(sh��)�ı��^���Լ������(sh��)ָ��ėl����(zh��)�С�SHARC֧��IEEE-754�ξ��ȸ��c��(sh��)��23-bitβ��(sh��)��8-bitָ��(sh��)�Լ���̖λ����40-bit�Uչ����IEEE��ʽ��32-bitβ��(sh��)����
�_�l(f��)֧��
ADI��˾��ܛ����Ӳ���_�l(f��)���߰���ԓ��˾��VisualDSP�����_�l(f��)�h(hu��n)�����ھ����������_�l(f��)����VisualDSP�ṩ����(y��u)����C���g�����R�������B�������{(di��o)ԇ���Ľӿڡ�ԓ��˾�ķ������m����ͨ�õĴ��ڿ�����PCI���Լ���̫�W(w��ng)���Cƽ�_����EZ-Kit Lite����һ���u��������ġ��������Rȫ��VisualDSP����SHARC�R���Z����һ�N����(sh��)ʽ�Z������A(ch��)��
Lucent
DSP-16xx
DSP 16000
DSP 16xx
�Y(ji��)��(g��u)���c
16-bit���cDSP
����16316-bit�ij˷���
36-bit��ALU/���
����Ƭ�N����Ƭ��(n��i)ROM
������2.7-4.75V
����ָ��
�Ηlָ��/�Kָ���Ӳ��ѭ�h(hu��n)���l���ӳ����{(di��o)�ã����^����ό�ַ��ָ��(sh��)�z�y��bitλ��ȡ����λ����Q���]�����D(zhu��n)ָ�
�_�l(f��)֧��
��Ӳ���_�l(f��)ϵ�y(t��ng)�����ھ����������u�������ʾ�塣ܛ���_�l(f��)���߰����R����/�B�������{(di��o)ԇ����ܛ�������͑��ó���졣EDA�S��߀�ṩ��DSPܛ������ģ�K�����ϵ�y(t��ng)���ķ��湤�ߡ�
DSP 16000
�Y(ji��)��(g��u)���c
�pMAC��Ԫ
֧��16332-��32332-bit�ij˷�ALU
֧��16-��32-��40-bit�\��
X��Y�惦������32-bit��(sh��)��(j��)����
��ַģʽ
�Ĵ����ʹ惦��ֱ�ӌ�ַ���Ĵ����g�ӌ�ַ��������(sh��)��ַ�Լ��Ĵ���+�ÓQ��ַ�������������ṩλ����?q��)�ַ��ֻ����ܛ���팍�F(xi��n)��֧�փɂ����l(f��)��ѭ�h(hu��n)���_������ַģʽ����ָ����g(sh��)�\�㡣
����ָ��
֧��16-bit��32-bit�Ļ��ָ�����D(zhu��n)����Ҫ�����C�����ڣ��S��ָ��ėl����(zh��)�п��Ա����D(zhu��n)�ơ�Redoָ����������\����doָ���b��cache�Ĵ��a���������a��������Viterbi���^ָ��Ĉ�(zh��)�У����a(ch��n)��ģʽ���Ƶ�Ч�������⣬�Ñ�����ʹ�ñ��^ָ���Q��Viterbi̎������С����ͨ��������������ָ��߀�����D(zhu��n)��ȡؓ��ȡ�^��ֵ�Ͷ��c���g(sh��)�\�㡣
�_�l(f��)֧��
ܛ�����߰���ANSI C ���g�����R�������B�������{(di��o)ԇ����ܛ��������Ӳ�����߰����ھ����������_�l(f��)�塣����Gnu C��C���g���M�оֲ���ȫ�ֵă�(y��u)�����Ա��M��CԴ���a���{(di��o)ԇ��Ҳ����C�ͅR����ϴ��a���{(di��o)ԇ���R����֧��ANSI C�A̎�������S�ļ����������ÓQ���l���R�����Լ����N����(sh��)��ʽ��ԓ�R����߀���S���_ʽ���������Ñ����x�Ę�̖����֧���A̎���ָ�ʹ�R�����c�{(di��o)ԇ���������\�㡣�{(di��o)ԇ��֧�ֆ������ͬĻ�ͬ�̎�����ļ����{(di��o)ԇ��֧�֔�(sh��)��(j��)��ָ����c���ӽ����r��ܛ�����桢��ϵ�C���a�ͅR�����a�{(di��o)ԇ���V���Ĵ��a��������TargetViewͨ��ϵ�y(t��ng)ͨ�^JTAG���������Ļ��B�W(w��ng)��Ӳ�����桢Ӳ����ۙ���Լ�Ƭ��(n��i)������Ӌ��(sh��)���V����Ƭ��(n��i)�{(di��o)ԇӲ�����Ԍ��r�O(ji��n)ҕ�S��̎���������{(di��o)ԇ���Іβ��\�д��a�r�����ԈD�λ����@ʾͨ�^DSP�Ĕ�(sh��)��(j��)�����@�ӣ��Ñ������^�쵽̎�����Л]�г��ʹ�õIJ��֣��Ĵ��a�����Ч�ʡ�Synopsys COSSAP, Cadence SPW, �Լ� Mathworks Matlab �ȵ������Ĺ���Ҳ֧�� DSP16000�ķ��档ܛ�����ߵăr���1500���A��Ӳ�����ߵăr���5000��7000���A��
Motorola
DSP-56800
DSP 563xx
DSP 56800
�Y(ji��)��(g��u)���c
16-bit���cDSP
���п��ƹ��ܵ�DSP
�����Д��Ӳ��doѭ�h(hu��n)
������2.7V��70MHz
��ַģʽ
�Ĵ���ֱ�ӌ�ַ���̵Ļ��L�Ĵ惦��ֱ�ӌ�ַ���߂��惦���g�ӌ�ַ���Լ�������(sh��)��ַ��߀֧�̵ֶ��D(zhu��n)��ƫ�ú�ѭ�h(hu��n)���_����ģ��(sh��)Ӌ�㡣
����ָ��
��������ָ���Kָ���Ӳ��do��repeatѭ�h(hu��n)���cALU�\�㲢�еĆ����p�IJ��а���ָ���ȡָ���ͬ�r���S���ɂ��惦���L�������S���κμĴ�����惦����λ���������������ڳ˷���MAC��ͬ�r����ȡ�����ӡ��p��ƽ����ʹ��һ���l���D(zhu��n)��ָ��ͱ��^ָ����F(xi��n)�����ͷ���㷨������ض��ėl�����棬�tDSP��(zh��)�Џ�һ���Ĵ�������һ���Ă�ݔ�����磬�惦һ����(sh��)�������ֵ������ֵ����
�_�l(f��)֧��
ʹ��OnCE�ڣ�ͨ�^JTAG�ӿ���Ƭ�Ϸ��档CodeWarrior�ṩ���ɵ��_�l(f��)�h(hu��n)�������а���C���g�����R�������B������ܛ���������Լ��D�λ���Դ���a�ͅR�������{(di��o)ԇ�������u��ģ�K��DSP56824EVM���_�l(f��)ϵ�y(t��ng)��DSP-56824ADS��
DSP 563xx
�Y(ji��)��(g��u)���c
24-bit���cDSP
����ˮ�������ɂ�ȡָ��һ����a���ɂ���ַ�a(ch��n)�����Լ��ɂ���(zh��)��
���Зl��ALUָ��
�ԼĴ�������A(ch��)�ĽY(ji��)��(g��u)
�c�ˈ�(zh��)�І�Ԫ���l(f��)����ͨ��DMA����
����(sh��)����������3.3V��������5V��I/O��������������1.8V,����3.3V��I/O
�c�˲��й����ĞV�����f(xi��)̎����
����ָ��
Ͱ����λ��֧�ֶ�bit��λָ������ڃɂ��������Ƅ������λ��ԓ��λ��߀֧��bit�������c�a(ch��n)����֧�ֲ���ALUָ��ėl����(zh��)�С�����yԇ�l����٣��t̎������(zh��)��NOPָ�563xx��(zh��)��16-bit�����g(sh��)�\�㣬�@�����T��LD-CELP�ȉ��s�㷨�dz����á�ͨ������24-bit�ĽY(ji��)��(g��u)����16-bit���\��r�����ܕ��������ͣ��������ܛ����24-bit�Ĕ�(sh��)�������\�㡣
�_�l(f��)֧��
�_�l(f��)ϵ�y(t��ng)���������u��оƬ��Ŀ��ϵ�y(t��ng)��ԓϵ�y(t��ng)���������_�l(f��)ģ�K�����C�ӿڿ��������D(zhu��n)�Q�����R������ܛ���������Լ�C���g������JTAG����A(ch��)��OnCE�ڿ����ڌ��r�z�����еă�(n��i)��������ӛ�����ʮ���lָ�MOTOROLA�ṩ����DSP563xxϵ�е����b��56�NӲ���ĺ�ܛ���Ĺ��ߡ��������Ĺ��߰���Tasking�ľ��g�����{(di��o)ԇ����Domain Technologies���{(di��o)ԇ����
Lucent/Motorola
StarCore SC100
StarCore SC100
�Y(ji��)��(g��u)���c
16-bit���cDSP��
DSP�Y(ji��)��(g��u)��������
��׃�L��ָ����ߴ��a��Ч�ʺͲ�����
���õ�C�����g��
��ַģʽ
�Ĵ���ֱ�ӌ�ַ����ַ�Ĵ����g�ӌ�ַ���c����Ӌ��(sh��)�����P(gu��n)�Č�ַģʽ���Լ���������(sh��)��Q�����dȤ�Ĕ�(sh��)��(j��)���ַ�����⌤ַģʽ��
����ָ��
SC140�Ķ����˷���֧�֎���̖�ĺ͟o��̖������(sh��)������С��(sh��)�c����(sh��)��ʽ���\�㼰����N�M�ϡ���MAC��Ԫ֧�ּӡ��p��ȡؓ��ȡ�^��ֵ���Լ����㡣MAC��Ԫ߀֧�ֳ��������^�����ֵ/��Сֵ�\�㣬�ڼĴ��������g(sh��)��λ��ȡ��֮�g�D(zhu��n)�ơ�ͨ�^���Ĵ����е�ֵ�����Ǵ���Ɍ���16-bit�IJ�����(sh��)��֧�ֆ�ָ�����(sh��)��(j��)��SIMD�������ֵ/��Сֵ���ӡ��p��MAX2��ADD2��SUB2����ʹ���@Щָ������چ����ڃ�(n��i)��(zh��)�а˂��ӷ��������ֵ/��Сֵ�\�㡣SC140����һ�����T�����ֵ/��Сֵ�\���Ԫ���;S�رȣ�Viterbi��������ָ��һ�������Ա���Ч�،��F(xi��n)�S�رȾ��a�㷨��
�_�l(f��)֧��
���_�l(f��)���߰����R��������(y��u)�������B������ܛ��������ANSI C���g�����cC11���ݵ�C/C11���g����ԓ���g��֧��ITU/ETSI�˜ʡ�
Texas Instrument
TMS320C2000
TMS320C5000
TMS320C6000
TMS320C2000
�Y(ji��)��(g��u)���c
16-bit���cDSP
����Y(ji��)��(g��u)֧�փɂ����_�Ŀ����Y(ji��)��(g��u)
�p�L��RAM���S��ͬһ�����ڃ�(n��i)�x��?q��)�RAM�ɴ�
������3.3V
�C�Ͻ�B
TI��TMS320C2000 DSP�ǻ���320C2xLP�ˡ�C2xLP�˾���4����ˮ��������40MHz������JTAG����ģ�K��
C2xLP��һ���������g(sh��)߉��Ԫ��CALU������32-bit���ۼ�����Acc����AccҲ��CALU��һ��ݔ�롣Acc������ݔ�����16316-bit�ij˷���ͨ�^������λ�����Լ�ݔ�딵(sh��)��(j��)������λ����ܛ������ͨ�^�Mλλ���D(zhu��n)Acc�ă�(n��i)�ݣ��팍ʩλ�����͜yԇ��
���ˌ��F(xi��n)С��(sh��)�����g(sh��)�\�����CС��(sh��)�ij˷e��C2xLP�ij˷e�Ĵ�����ݔ��ͨ�^�˷e��λ�����������\���Юa(ch��n)���Ķ������bit��ԓ�˷e������λ�����S��128���˷e�ۼӶ������a(ch��n)������������ij˷e�ۼӣ�MAC�����ڣ�������һ����(sh��)��(j��)�惦����ֵ����һ������惦����ֵ�������Y(ji��)���ӽo�ۼ�������C2000ѭ�h(hu��n)��(zh��)��MAC���t����Ӌ��(sh��)���Ԅ���������������ጷŽo�ڶ���������(sh��)���Ķ��_�������ڈ�(zh��)��MAC��
C2xLP�����L��64000��16-bit��I/O�ڡ�C2000�����O(sh��)���T�紮�ڡ�ܛ���ȴ���B(t��i)�l(f��)�����ȶ�ӳ��锵(sh��)��(j��)��I/O���g���Ñ�������ʹ��������I/O��ַ���L��ӳ����I/O���g��Ƭ�����O(sh��)��C2000ϵ���еĶ���(sh��)оƬ���Ԯa(ch��n)��0-7���ȴ���B(t��i)��
C2000ϵ����C20x��C24xϵ�нM�ɡ�C20x��Ŀ���ǵ����ܵ�����O(sh��)�䣬��C24x��Ŀ���ǔ�(sh��)�ֻ����R�_���ơ�
C24xϵ�е�оƬ�����¼����������Ա�֧���R�_���ơ�ԓ�¼�����������������/�p���r���;ł����^�������ԺͲ��ήa(ch��n)��߉��Ϯa(ch��n)��12PWM��ݔ����֧��ͬ���ĺͮ�����PWM�a(ch��n)������߀֧��һ�����g����PWM��B(t��i)�C�����_�P(gu��n)���ʾ��w�܁팍�F(xi��n)�������L���w�ܵĉ����ͽ����ġ�һ���P(gu��n)�C�ήa(ch��n)����ԪҲ�����ڱ��o���ʾ��w�ܡ����⣬�¼�������߀�������Ă��ɼ�ݔ�룬���еăɂ����ڹ⾎�a�������}�_��ֱ��ݔ�롣
C24xϵ�е�оƬ߀������10-bit��A/D׃�Q������500ns�ĕr�g��(n��i)��ģ�M��̖��׃�Q������߀��8����16������ݔ��ͨ������Щ�µ�C24xϵ�е�оƬ߀���Ԅ�������������������16��׃�Q��һ�������IJɘ�/���֣�S/H���A��������ͨ�^֧�ֲ�ͬ��ݔ���迹���o�Ñ��ԘO����`���ԡ���ЩC24xϵ�е�оƬ��8K-32K�ֵ��W�q�惦����flash����
��ַģʽ
������(sh��)��ַ����퓵Ĵ惦��ֱ�ӌ�ַ��ָ�����7-bit�͔�(sh��)��(j��)�ָᘵ�9-bit�γɔ�(sh��)��(j��)�惦���ĵ�ַ�����Ĵ����g�ӌ�ַ��ʹ��8���o���Ĵ����е�һ�������o���Ĵ����Ԅ�������p����ַ���]��ѭ�h(hu��n)���_��
����ָ��
MAC�͔�(sh��)��(j��)�Ƅ�ָ�MACD�������ˌ�Ƭ��(n��i)RAM�Ĕ�(sh��)��(j��)�K����MAC��Ԫ����CPUʹ��ݔ��Ĕ�(sh��)��(j��)ֵ�r��CPU��ԓ��(sh��)��(j��)ֵ������һ���惦����Ԫ��MACDҲ��ʹ��ѭ�h(hu��n)���_����һ��������������ھ��e�͙M��V�����Ǻ����õġ�C2000��������ָ��ѭ�h(hu��n)���˷����ۼ�ǰһ���e���˷����pȥǰһ���e���ۼ�ǰһ���e���ƄӔ�(sh��)��(j��)�����l���D(zhu��n)�ƺ��{(di��o)�á����L������(sh��)����(sh��)��(j��)�惦����������������D(zhu��n)�ۼ�������(sh��)��(j��)�K�Ƅӡ�
�_�l(f��)֧��
TI��Code Composer4.10��һ�����ɵ��_�l(f��)�h(hu��n)����֧�־����������{(di��o)ԇ���������Ŀ�������@���rֵ��1995���A���_�l(f��)�h(hu��n)������ANSI C���g�����R�������B������ܛ�����������r����������(sh��)��(j��)�ǿ�ҕ���ġ�TI�ķ�����֧��JTAG�Dz���ʽ��߅�������档ԓ��˾Ҳ�քe�ṩC���g�����R�������B������ܛ�����������r�������͑��ó���졣�����������ṩ�u��ģ�K�����������Լ������㷨��
TMS320C5000
�Y(ji��)��(g��u)���c
16-bit���cDSP
C55x���pMAC��Ԫ��C54x�І�MAC��Ԫ
C55��ָ���L�ȿ�׃���қ]����꠵�����
C55x��12�M������C54x��8�M����
������0.9V��300MHz
�C�Ͻ�B
C5000��16-bit���cDSPϵ�У������f�е�C5x����ǰ������C54x�����µ�C55x��
C55x��C54xԴ���a���ݣ���C5x��C2xԴ���a���ݡ�C54x�P(gu��n)ע�ڵ��ģ���C55x�t�������ᵽһ����ˮƽ��300MHz��C55x��120MHz��C54x��ȣ��������5���������Ąt��������֮һ���M��C5x߀��ȫ�����a(ch��n)������˾�ѽ�(j��ng)�����O(sh��)Ӌ�D(zhu��n)��C54x ��C55x��C54x ��C55x���ø��M�Ĺ���Y(ji��)��(g��u)��
C55x ����12�M�����Ŀ�������C54x�t��8�M����������һ�M�����������ij����ַ������C54x�����Č��Ȟ�16-bit����C55x�����Č��Ȟ�32-bit��C55x�����M��(sh��)��(j��)�x�����̓ɽM��(sh��)��(j��)����������C54x�ЃɽM��(sh��)��(j��)�x������һ�M��(sh��)��(j��)��������ÿ�M��(sh��)��(j��)���������������ĵ�ַ������C55x�Ĕ�(sh��)��(j��)��ַ�����Č��Ȟ�24-bit����C54x�Ĕ�(sh��)��(j��)��ַ�����Č��Ȟ�16-bit��
C54xʹ�Ãɂ��o���Ĵ������g(sh��)��Ԫ����ÿ�����ڃ�(n��i)�a(ch��n)��һ����ɂ���(sh��)��(j��)�惦����ַ���@�ĽM��(n��i)�������̓ɂ���ַ�l(f��)����ʹ������M�ж������(sh��)�\�㡣
C55x�ĵ�ַ-��(sh��)��(j��)����Ԫ��ADFU�������ˌ��T��Ӳ����������M��(sh��)��(j��)������ԓADFUҲ��������ͨ�õ�16-bit ALU�����ں��ε����g(sh��)�\�㡣ԓALU��ָ��_��Ԫ��IU������������(sh��)���ʹ惦����ADFU�Ĵ�������(sh��)��(j��)Ӌ���Ԫ��DCU���Ĵ�������������Ԫ��PFU���Ĵ������p��ͨ�š��oՓ��ALU��߀��������ַ�Ĵ���ALU��ARAU���е�һ���������������g�ӌ�ַ�ľł���ַ�Ĵ������@����ARAU��C55x�����M��(sh��)��(j��)�x�����ṩ�����ĵ�ַ���@�N�����Ա��C����ÿ��CPU���ڃ�(n��i)DCUȥ�x�ɂ�16-bit�IJ�����(sh��)��һ��16-bit��ϵ��(sh��)��
C55x��DCU�����˃ɂ�MAC��Ԫ���چ����ڃ�(n��i)���ɂ�17217-bit��MAC�\�㡣��߀������һ��40-bit��ALU���Ă�40-bit���ۼ����Ĵ�����һ��Ͱ����λ�����Լ����T��Viterbi�㷨Ӳ����ÿ��MAC��Ԫ����һ���˷����͎�32-��40-bit�߉�ļӷ�����������(sh��)��(j��)�x�������ɂ���(sh��)��(j��)����һ������ϵ��(sh��)���ͽo�ɂ�MAC��Ԫ���Ñ�������ALU��32-bit���\�㣬����_���ɂ�16-bit���\�㡣���_����DCU��40-bit Acc�Ĵ�������ݔ���⣬ALU߀��IU����������(sh��)�����ʹ惦����ADFU�Ĵ�����PFU�Ĵ������p��ͨ�š�
C54x�dž�17217-bit MAC�C������һ��40-bit�ļӷ������ɂ�40-bit��Acc��һ�����_��40-bit��ALU���cC55x����ƣ�C54x��ALUҲ�������Ƀɂ�16-bit�����ã���Ƀɂ��������\�㡣�˷���ݔ��̎��40-bit�ļӷ������S������ˮ��MAC�\�㣬�Լ����еăɂ��ӷ��ͳ˷��������ښwһ����ָ��(sh��)���a֧�ָ��c��(sh��)�\�㡣
�ɂ�ϵ�еĽY(ji��)��(g��u)��֧��һ��Ͱ����λ������40-bit��Acc��ֵ���ƻ���������_31bit��ԓͰ����λ������λ���ֵ�ͽoDCU��ALU���Ա����Mһ�����\�㡣ָ����P(gu��n)�ڶ�������(sh��)����������(sh��)��32-bit������(sh��)��ָ�֧�ֽY(ji��)��(g��u)�IJ����ԡ��˂����Ԫ�����ַ���o���Ĵ�����ܛ���ї������C���g����Ч�ʡ�
C55x���Ԉ�(zh��)�п�׃�L�ȵ�ָ��@��C54x���@���IJ�ͬ��C54x��ָ���L�Ȟ�̶���16-bit����C55x��ָ���L�Ȅt��8��48 bit��C55x��IU����64 byte�Ĵ��a������һ����a߉���_�J��׃�L��ָ���и�ָ��ą^(q��)�e���ֲ�ѭ�h(hu��n)ָ��ʹ��ָ��_��Ё�ѭ�h(hu��n)��(zh��)�д��a�K��ָ��_���߀�����ڈ�(zh��)�Зl������������ָ��ėl���yԇ�r���Ɯy�Ե���ȡָ�ָ���a�����������?q��)�ָ���a�������Lj�(zh��)�ЄӑB(t��i)�r�Ķ��������A���ĕr�g�õ��Y(ji��)����
C55x��PFU��ۙ����Ĉ�(zh��)���c��������_16Mbyte�ij���惦���a(ch��n)��24-bit�ĵ�ַ��ԓ��Ԫ��Ӳ����������ѭ�h(hu��n)���`�����D(zhu��n)�ơ��l����(zh��)�С��Լ���ˮ���o���Ϊ��ij���Ӌ��(sh��)�����Ա��C���ӳ�����Д�����ӳ�����ٷ��ء�ԓPFU߀��������ָ����ˮ���Ă�CPU��B(t��i)�Ĵ�����߉������Ӳ����ʽ�����ṩ�ČӉKѭ�h(hu��n)Ƕ�ס���Ӳ��߀֧�֗l��ѭ�h(hu��n)��PFU̎����ˮ����ð�U�������x�������x�ṩ���o������ָ�������@�Nð�U�l(f��)���r����ˮ���o߉�Ͳ���һЩ���ڣ����C��������_��(zh��)�С����ɵ�ܛ���ȴ���B(t��i)�l(f��)����ʹ�Ñ�����ʹ���^�����ⲿ�惦����
ԓϵ�е�����DSP��֧��Ƭ��(n��i)�p�L��RAM��DARAM�����Ñ����Ԍ������Þ����惦����(sh��)��(j��)�惦����C55x߀�ДUչ��ͬ��ͻ�l(f��)��RAM��ͬ��DRAM�ͮ���SRAM��DRAM��Ƭ��(n��i)���i��h(hu��n)��PLL�����S�Ñ����ƕr犣���C55x��߀���Լ����c�Ԅӹ���Ƭ��(n��i)���O(sh��)�ʹ惦���Ĺ��ġ����������L��Ƭ��(n��i)�惦���r�������͕����ГQ������ģʽ��̎������Ƭ��(n��i)���O(sh��)Ҳ�ṩ��ƵĿ��ơ�
C55x߀�O(sh��)�����Ñ��ɿصĵ���IDLE����CPU��DMA�����O(sh��)���ⲿ�惦���ӿڡ�ָ����С��Լ��r犰l(f��)���·��
��ַģʽ
C54x֧�ֆΔ�(sh��)��(j��)�惦��������(sh��)��ַ��32-bit������(sh��)��ַ��߀ʹ�ò���ָ��֧���p��(sh��)��(j��)�惦��������(sh��)��ַ����Ҳ�ṩ������(sh��)��ַ���惦��ӳ�䌤ַ��ѭ�h(hu��n)��ַ��λ����?q��)�ַ�?/p>
��C54x�Ļ��A(ch��)�ϣ�C55x߀֧�ֽ^��ֵ��ַ���Ĵ����g�ӌ�ַ��ֱ�ӌ�ַ����λ��ģʽ��C55x��ADFU�������T�ļĴ�����֧��ʹ���g�ӌ�ַָ���ѭ�h(hu��n)��ַ������ͬ�rʹ���傀������ѭ�h(hu��n)���_�������������ľ��_���L�ȡ��@Щѭ�h(hu��n)���_���]�е�ַ��꠵����ơ�C54x֧�փɂ������L�ȵ�ѭ�h(hu��n)���_����
����ָ��
C54x�Ќ��T����ָ���FIR�V��������ָ���Kָ��ѭ�h(hu��n)���˂�����ָ��粢�д惦��˼ӣ����˷��ۼӺ͜p��ʮ���˷�ָ����˂��p������(sh��)�惦�����ơ�C55x߀�Ќ��T��ָ�����������ӵĹ��܆�Ԫ�Ͳ��������ă�(y��u)�c���Ñ����x�IJ��ЙC�ƣ����S����(zh��)�Ѓɂ�������ָ����ԽM�ϡ�
�_�l(f��)֧��
eXpressDSPܛ�����g(sh��)����DSP�����_�l(f��)���ߣ��������Č��rܛ�����A(ch��)�����؏�ʹ�õđ���ܛ���ӿژ˜ʡ��Լ��������ӵĵ�������ܛ��ģ�K��Code Composer Studio��һ�����ɵ�DSP�_�l(f��)������������C5000��C���g����DSP/BIOS�����r��(sh��)��(j��)���Q���g(sh��)�ȡ�
����
�F(xi��n)�ڣ����ڏ��s��Ӳ�������ѽ�(j��ng)���ɵ��˜ʼ����·�У�ϵ�y(t��ng)�_�l(f��)�ˆT���ȑ�ԓ֪������x����m��оƬ��Ȼ����ڴ�Ӳ���Y(ji��)��(g��u)�O(sh��)Ӌܛ����ϵ�y(t��ng)�O(sh��)Ӌ���ЃɷN�x��ʹ�Ì��ü����·��ɾ���DSP���F(xi��n)��̖̎�������֮�£��ɾ���DSP�Ѓɂ���(y��u)�c��
�ɔU���ԣ��O(sh��)Ӌ�߿��Ը���(j��)Ҫ���̎��Ч�ʣ�����Ҫ���YԴ�����w�x��DSP�������Ƭ��(sh��)��
�������ԣ���Ӳ���������D(zhu��n)���ɱ��^����������ܛ���Ąӡ�
ʹ�ÿɾ���DSP�r����회�оƬ�ĸ��N�YԴ(����CPU,�惦�^(q��)�����O(sh��)��)���Թ���Ҏ(gu��)����ͨ�^DSP/BIOS�����p�ɵ�����@Щ������
TI��˾TMS320C5000ϵ�ж�����Ƕ��ʽDSP/BIOS�����к��Č��r�������΄Ռ��r����������������Ч������Ŀ���_�l(f��)Ч�ʣ�������F(xi��n)����Ҫ���r���΄յĴ���ϵ�y(t��ng)�С��D1��DSP/BIOS�IJ����Y(ji��)��(g��u)��
DSP/BIOS II����
TI��˾��DSP/BIOS II ����DSP/BIOS I ���A(ch��)�ϵĔUչ����֧�ָ����ܛ��ģ�K��ͨ�^�ă�(n��i)���ṩ����ʽ���΄շ��գ����т��y(t��ng)����̎��ϵ�y(t��ng)�ă�(n��i)�˷��ռ��ɞ�ɜyԇ��(n��i)�ˣ����������O(sh��)�䪚����I/O��(sh��)��(j��)��ģ�ͣ��^�m(x��)�������еĔ�(sh��)��(j��)�ܵ����������˄ӑB(t��i)��(n��i)������c��(n��i)�������
TI���_�l(f��)ƽ�_CCS IDE 2.0�м�����DSP/BIOS II�����Ԍ������M�Ќ��r��ۙ�c��������ߑ��ó����_�l(f��)�Ŀɿ��ԡ�������CCS����Ќ��r�^��DSP/BIOS��(n��i)���и����̵Ĉ�(zh��)�Р�B(t��i)�c����Į�ǰ���ԡ�ͨ�^�O(sh��)�ù��ߣ��_�l(f��)�߿��Ԍ�����ģ�K�������á�
DSP/BIOS II ����API���g(sh��)
Ŀ�ˑ��ó���ͨ�^�{(di��o)��DSP/BIOS II��API���@���\�Еr�ķ��ա�һ����DSP/BIOS II ģ�K���Թ�����Nă�(n��i)�ˌ���������(j��)ȫ�օ������O(sh��)�������������О顣DSP/BIOS II ���Ԛw�{������N�
��(n��i)�ˈ�(zh��)�о��� 
�D1 DSP/BIOS �����Y(ji��)��(g��u)�D
�D2 ���̃�(y��u)�ȼ�ʾ��D
�D3 ��(sh��)��(j��)��ʾ��D
�D4 ��(sh��)��(j��)�ܵ�ʾ��D
DSP/BIOS II�ṩ���ͬ�Ĉ�(zh��)�о��̡�ÿһ����־��в�ͬ�Ĉ�(zh��)�С����Ⱥ͑Ғ����ԡ�DSP/BIOS II ֧�փɂ��߃�(y��u)�ȼ����Дྀ�̺����Ȃ�õĺ��_���e�^��ѭ�h(hu��n)����(n��i)�ˈ�(zh��)�о���ͨ�^HWI, SWI��IDLģ�K�M�й��������⣬DSP/BIOS II���ṩ�˶��΄վ�������^�õ�����΄��g��ͬ��������TSKģ�K���������κΈ�(zh��)�Еr�̞�Ғ�ͻ֏͈�(zh��)��ͬ���������{(di��o)�������������΄յă�(y��u)�ȼ����@�Nͬ�������΄սo���l(f��)ϵ�y(t��ng)�O(sh��)Ӌ�ṩ�����õĻ��A(ch��)��
Ӳ������
DSP/BIOS II �ṩӲ����߉�ӿڡ���������Ӳ�����F(xi��n)������Ӳ�����ֵ��L�������ã���(n��i)��ӳ�䡢Ƭ��(n��i)���r����Ӳ���Д���M�г������ˑ��õ���ֲ����ͨ�^��ҕ�����O(sh��)�ù��߶��x��(n��i)��ӳ�䡢�Д��������������r�����̣�����ɄӑB(t��i)�ă�(n��i)������cጷš�
�O(sh��)�䪚��I/O
�O(sh��)�䪚��I/Oģ�K��(zh��)�Д�(sh��)��(j��)��ݔ���գ���ݔ������DSP�c���O(sh��)֮�g�Ͷྀ��֮�g�M�С�DSP/BIOS II ֧�֔�(sh��)��(j��)�ܵ�(pipe)�͔�(sh��)��(j��)��(stream)�ɷN���ͷ�ʽ����(sh��)��(j��)�ܵ������x������֮�g���ق��͔�(sh��)��(j��)��С�ͽy(t��ng)һ��������(sh��)��(j��)���龏�_�����������`����ʹ֮�m�����V������(sh��)��(j��)�������������ڵ��O(sh��)���(q��)�������@�N�O(sh��)���(q��)�������b���O(sh��)�䪚���Č����c�������ڔ�(sh��)��(j��)ͨ�^�ѯB(stacking)�C�Ƃ��͕r���O(sh��)���(q��)�����܉��(zh��)�Д�(sh��)��(j��)̎���������(q��)�����ڔ�(sh��)��(j��)ͨ���Ќ�����ˮ��̎����PIP��SIOģ�K�քe����Ŀ�ˑ����еĔ�(sh��)��(j��)�ܵ������Ă��ͷ��ա�SIOͬDEVģ�K�Y(ji��)�ϣ�ʹDEVͨ�^SIO�l(f��)�ͺͽ��Ք�(sh��)��(j��)��
�����g��ͨ�ź�ͬ��
DSP/BIOS II �еľ����gͨ�ź�ͬ��ģ�K֧�ֶ��΄ա���̖��(semaphores)������Ҫ��ͬ����ʽ���΄��\����̖������ͬ���YԴ�L����ͬ�����L�����O(sh��)�Ĕ�(sh��)��(j��)���_�^(q��)���Լ��L�������惦�^(q��)�����YԴͬ���ĵ�����������̖��߀���������΄Ո�(zh��)�е�ͬ������̖����SEMģ�K��������LCKģ�K�ṩ�����YԴ���Ѓ�(y��u)�ͻ��⡣��(sh��)��(j��)��п����ھ����gͨ�š��]��(mailbox)����ڔ�(sh��)��(j��)��У��܉����������΄�ͨ�š���(sh��)��(j��)�����QUEģ�K�������]��ģ�K��MBX������
���r����
���r����(TRA)ģ�K�ڑ��ó����(zh��)�����g�cDSP�Ŀ���r�������\�ࡣLOG,STS��TRCģ�K���@Щ�����M�й��������C�cĿ�˰�֮�g�Ĕ�(sh��)��(j��)��ݔ��������ʩ�����Ƿdz��P(gu��n)�I�ġ�DSP/BIOS�ṩHST��RTDXģ�K�������@Щ���ܡ�CCS IDE���ṩ���������N���r�������ߣ�
��CPUؓ�d�D
ؓ�d�D�ṩ����Ŀ��CPU��ؓ�d������CPUؓ�d�Ķ��x�dz�ȥ��(zh��)����̓�(y��u)�ȼ��΄�����ĕr�g������̓�(y��u)�ȼ��΄���ֻ���������̶����\�Еr�ň�(zh��)�е��΄ա���ˣ�CPUؓ�d������Ŀ�������C���͔�(sh��)��(j��)�͈�(zh��)�и��Ӻ��_�΄�����ĕr�g��
������(zh��)�ЈDʾ
�ڈ�(zh��)�ЈDʾ�����У��҂����Կ����������̵Ļ�ӷ�ʽ����(zh��)�ЈD��ˢ�����ʿ���ͨ�^RTA���ư��O(sh��)�����D����߀��������̖���Ļ�ӣ������Ժ���(sh��)��ӛ(tick)���͕r�ģ�K��ӛ����(zh��)�ЈDʾ�����w�Ͽ����Ŀ���о��̵Ļ�Ӡ�B(t��i)��
�������Cͨ������
�����ŵ����ƴ��ڿ����ļ������ڶ��x�����Cͨ���ϣ������ŵ��ϵĔ�(sh��)��(j��)��ݔ�Լ��O(ji��n)�y��(sh��)��(j��)��ݔ������
������Ϣӛ�
�x��ijһӛ������Ĵ˴��ڿɿ��������\�е���Ϣӛ䛡����C��Ŀ�˰�@ȡDSP/BIOS��(sh��)��(j��)���g��ӛ���Ϣ���@ʾ�ڴ˴����С��_�l(f��)�߶��x��ӛ���ϢҲ�@ʾ�ڴ����С�
�����y(t��ng)Ӌ�^��
�y(t��ng)Ӌ�^�촰����Ӌ����¼���׃�����F(xi��n)�ĴΔ�(sh��)���o�������ֵ����Сֵ��ƽ��ֵ���O(ji��n)�y���r�r�g��׃������ֵ�Č��Hֵ������ֵ�
�������r�������
�����\�Еr�g�в�ͬ����M��ۙ���ƣ���Ĭ�J��r�£�������͵ĸ�ۙ�������S�ġ����ۙ����һ�N��ͣ����ʹ��ȫ�����C(GLOBAL HOST)��ͨ�^���r��׃���ư�Č��ԣ�߀�����O(sh��)�����r�������ߵ�ˢ���l�ʡ�
- 3�N��̖�ɹ��x��4300��4000PL�Լ�4000
- ʹ����������Թ����õ���|�yԇ�x�����Ԍ���|���|�M�Мyԇ���J�C�Լ��ęn�䰸�����ø��ٔ�(sh��)��̎�����g(sh��)�M�п��ٵĜyԇ��
- �������\���ʹ�����ų����ӿ��ٺ���
- ȫ�� PM06!�yԇ�^�ǵ�һ�����Ԝyԇ Cat 6 �Ƿ���Ϙ˜��Լ������Ե����ԡ����β��^
- �µ������·�m�����ɫ@�ø���ġ�ͨ�^���Y(ji��)���������e�`�ġ�ʧ�����Y(ji��)��
- ������Ĺ��|�yԇ�m�����Ɉ�(zh��)���p���|���p���L�Ĺ��|�J�C
- ʹ�� LinkWare? ��|����ܛ�����Է���،���|���|�M�й������ęn�䰸
- ֧���Ї����Ҙ�
���ڸ��ٵ��~�|���|��DSP-4300��(sh��)��ʽ��|�����x����ȫ�����|�yԇ����C���ߡ����������������@�þ��_�Ĝyԇ�Y(ji��)����
- ���^5���5�6��yԇ��Ҫ����������ȣ���չ��DSP-4000�Ĝyԇ��������ͬ�r�@�� UL �� ETL SEMKO���J�C
- ʹ���µ�ͻ���Ե������·�m�����ɵõ�������ʴ_�ġ�ͨ�^���Y(ji��)����DSP-4300�а���ԓ�m����
- �S�C�ṩ6�ͨ���m������һ��ͨ��/�����m�������Ķ����_�yԇ6�ͨ��
- �Ԅ��\����|���ϣ�����Ӣ�ߜʴ_�@ʾ����λ��
- �Uչ��16MB���弯�ɴ惦���ɴ惦һ����Ĝyԇ�Y(ji��)����300����
- �Ɍ�����TIA-606A�˜ʵ���|ID̖���d��DSP-4300��(sh��)��ʽ��|�����x�У���(ji��)ʡ�r�gͬ�r�_���˔�(sh��)��(j��)�Ĝʴ_��
- �S�C�ṩ���ô惦���Լ���������|�yԇ����ܛ����
|
DSP-4000ϵ�Д�(sh��)��ʽ��|�����x�xָُ�� | ||||
|
|
DSP-4300 |
DSP-4100 |
DSP-4000PL |
DSP-4000 |
|
�˜�DSP-4300ϵ�а��b |
�� |
�� |
�� |
�� |
|
Cat6/5e �����·�m���� |
�� |
|
�� |
|
|
Cat6/5e ͨ���m���� |
�� |
�� |
�� |
�� |
|
Cat6/5e ͨ��/�����m���� |
�� |
|
|
|
|
���弯�ɴ惦�� �ɴ惦���_300���yԇ�Y(ji��)�� |
�� |
|
���H���ڸ�Ҫ�yԇ�� | |
|
��ý�w�����x���� |
�� |
�� |
|
|
- ȫ�µ���yԇϵ�y(t��ng)��Q�����������ߵ����ܣ��@�ø��ࡰͨ�^���Y(ji��)��
- �������ڲ����·�ӿ��m������ɵ�"ʧ��"�Y(ji��)������(ji��)ʡ�yԇ�r�g�ͳɱ���
- ���ڽ��hTIA/EIA-568-B�˜ʵľ��ȺͿ��؏Ͳ����ԡ�
- �Թ����ã����е��O(sh��)Ӌ���C�ڬF(xi��n)�����ز��p�Ĝyԇ��Ҫ��ľ��Ⱥͷ�(w��n)���ԡ�
- ����TIA/EIA-568-B�˜ʡ�
�M��˜�Ҫ���A�ø����ͬ
���b���ھW(w��ng)�j�\�е���|����ه�ھ��_�yԇ���J�C�yԇ�������˾W(w��ng)�j������6�ͨ���m�����߂������Ĝyԇ����������˜yԇ���ȡ�
�F(xi��n)������������DSP�ľ��ȁ�yԇ6�ͨ����DSP-4300��(sh��)��ʽ��|�����x������6�ͨ���m��������ʹ�����h���B���a�����g(sh��)�������Mһ�����������Եõ��������κ�һ�N�yԇ�x�����_��ͨ���yԇ�Y(ji��)���������挍�Ŀ�����|ϵ�y(t��ng)�����ܡ�
��(sh��)�֜yԇ���g(sh��)�ɵõ����õ��\�����ܣ�������ٶ��Լ����ߵĜyԇ����
DSP-4300ϵ�Д�(sh��)��ʽ��|�����x���Ј��ϵ�һ�_���ڿɔUչ��(sh��)�ֻ�ƽ�_�Ĝyԇ�x�����_���M���˜ʵ�Ҫ���@��ζ������DSP-4000ϵ�Д�(sh��)��ʽ��|�����x����������Ͷ�Y����ʹ������Ҳ���ܵ����o�ġ�
- ͬ�r�ڃɂ����L�yԇ�ɗl���|���ԄӴ��A�yԇ�Y(ji��)����
- �p��yԇ���y���|�����Y(ji��)�����A��һ��ӛ��С�
- ʹ����|����ܛ���M��ȫ��Ĕ�(sh��)��(j��)�����͈�����ɡ�
- �ԄӜyԇ�p�ġ��L�Ⱥ͂�ݔ�r�ӡ�
- ��C���|�Bͨ�ԣ��y���侀���Ϲ��|�B�ӵĽ��^��
- ͨ�^���|���h���M��ͨԒ��
- ��ۙ�yԇ�^����������С�Ĺ���ݔ����
- �ɳ��ܜyԇ�еĵ�������������¼�
�����˾W(w��ng)�j��DSP-4300ϵ�Д�(sh��)��ʽ��|�����x�����������LinkWare����|������ܛ����DSP-CMS����ʹ�����ɸ���(j��)�������c���͑��������ȿ��ٽM���������鿴����ӡ���惦��?q��)��yԇ�Y(ji��)���M�д�n�����Ԍ��yԇ�Y(ji��)���ϲ���һ���ѽ�(j��ng)���ڵĔ�(sh��)��(j��)���У�������(j��)��һ�ֶλ�(sh��)���@Щ��(sh��)��(j��)�M�����������Լ��ؽM��
- �D�Μyԇ��棬�ò�ɫ�D��������DSP-4300�yԇ�l�ʏ�1HZ��350MHZ�����б��y������(sh��)��
- �ı���ʽ�Ĕ�(sh��)��ʽ�R���yԇ��棨��ĵ���r�����Ĕ�(sh��)��(j��)�c��
- �ṩ���б��y��|�·���б�R����棬����һЩ�P(gu��n)�I��Ϣ
��Ŀǰ��ֹ����|���R�e���J�C����߀�]�м�����һ��ͨ�^(li��n)����|����ܛ����CMS���͘˺���˾�������˾W(w��ng)�j��˾�ѽ�(j��ng)�_�l(f��)���˼���ʽ�ęn��Q������
������ܣ�TMS320C6000? DSP ƽ�_C6000? DSP ƽ�_��������ܺͳɱ�Ч���ˮ�ʣ��ṩ�I(y��)������ DSP���\���ٶȸ��_ 1GHz��ԓƽ�_�� TMS320C64x? �� TMS320C62x? ���cϵ���Լ� TMS320C67x? ���cϵ�нM�ɡ������I(l��ng)������������A(ch��)�O(sh��)ʩ�����������l�Լ�ҕ�l/�������ܷ����� 1200 �� 8000MIPS�����c�������� 600 �� 1800MFLOPS�����c��������
����ģ�TMS320C5000? DSP ƽ�_���C���ĵ��� 0.12mW�����ܸ��_ 900MIPS��C5000? DSP �DZ������õ������x��������(sh��)��������������GPS ����������yʽ�t(y��)���O(sh��)�䡢MIPS �ܼ����Z���͔�(sh��)��(j��)̎���Ȃ��˺ͱ�yʽ�a(ch��n)Ʒ���Լ��O�佛(j��ng)����Ч�Ć�ͨ���Ͷ�ͨ�����á�TMS320C55x? ϵ���ṩ�I(y��)����͵Ĵ��C���ĺ����M���Ԅ��Դ������TMS320C54x? ϵ���ṩ�V�������ܡ����IJ����Լ����O(sh��)�ͷ��b���x��OMAP59xx DSP �� C55x DSP ��(n��i)���c TI ������ ARM925 �༯�ɣ��Ķ��ṩ���е��Č��r��̖̎�������� DSP �;�������Ϳ��ƹ��ܵ� ARM��
��(y��u)�����ƣ�TMS320C2000? DSP ƽ�_TMS320C2000? DSP ƽ�_��(sh��)�ֿ����ИI(y��)�ṩ��һϵ�Ѓ�(y��u)���оƬ��ԓƽ�_�������������Ŀ������O(sh��)���������ò����^���� TI һ�� DSP ���g(sh��)��̎��������Ч�ʡ�TMS320C28x? DSP ϵ�а�������Ƭ���W����_ 150MIPS ���ܵ� 32 λ�����������_���ݰ汾�� ROM��TMS320C24x? DSP ϵ���ṩ 20-40MIPS�����и߶ȼ��ɵ����O(sh��)���r��� 2.00 ��Ԫ���£���������
���ߺ�ܛ��TI �������N���õ��_�l(f��)���ߺ�ܛ��������֧�ֿ�����ɻ��� DSP �đ����O(sh��)Ӌ�^�� - �ĸ�����a/���g����(j��ng)�^�{(di��o)ԇ�������{(di��o)��(y��u)���ٵ��yԇ���S��߶��� TI �Č��r eXpressDSP? ܛ�����_�l(f��)���߲��Ե�һ���֣�ּ�ڎ��������_ʼ��
�o��ģ�M�a(ch��n)ƷTI �ṩ���N�o����(sh��)��(j��)�D(zhu��n)�Q�����Դ�������Ŵ������ӿں�߉�a(ch��n)Ʒ����������O(sh��)Ӌ�����S��M���У��@Щ����ּ�ڌ��T�c TI DSP �M���B�ӡ�Ҫ��
]]>
�c�F(xi��n)�ЏV����ȣ���(sh��)�����l�V����digital audio broadcasting�����Qdab���@�N�µĂ�ݔϵ�y(t��ng)�{�����T����(y��u)�c�������ˇ��Hͨ���ИI(y��)�IJ�Ŀ�����@����Ѹ�ٵİl(f��)չ���҇��V���Ӱ�ҕ�ИI(y��)�˜ʡ�30��3000mhz���攵(sh��)�����l�V��ϵ�y(t��ng)���g(sh��)Ҏ(gu��)������2006��6��1������ʩ�� ԓ�˜���dab�˜ʣ��m�����ƄӺ̶����ՙC�����|(zh��)����(sh��)�����l��(ji��)Ŀ�͔�(sh��)��(j��)�I(y��)�ա�
�����֙C�ҕ����2008�����W�\�ṩ���գ�����(n��i)��҆�λ�ѷe�O������dab�������_�l(f��)�����Č���Bdab���ՙC�ĘәC�O(sh��)Ӌ��
ϵ�y(t��ng)������Ҫ��
�W��dabϵ�y(t��ng)Ҏ(gu��)����4�Nģʽ�����O(sh��)Ӌ���õ��ǵ�1�Nģʽ�����w����(sh��)���1��ʾ�����У�l��ʾһ���ķ�̖��(sh��)��k��ʾÿ����̖�����d������(sh��)��tf��ʾһ���ij��m(x��)�r�g��tnull��ʾ�շ�̖���m(x��)�r�g��ts��ʾÿ����̖�ij��m(x��)�r�g��tu��ʾ��Ч��̖�ij��m(x��)�r�g���ı�ʾ���o�g���ij��m(x��)�r�g��

��1 ��1�Ndab��ݔģʽ�ľ��w����(sh��)
�����@һģʽ���O(sh��)ӋҪ��飺����1.536mhz���d���l��174��240mhz���`�a�ʲ����^10-4��
����ԭ�����O(sh��)Ӌ˼·
1 ����ԭ����D
dab���ՙCԭ����D��D1��ʾ��dab���ՙC�����쾀���յ�����̖��(j��ng)�^���l�^�D(zhu��n)�����lģ�M��̖���Ŵ���M��a/d׃�Q���õ���(sh��)����̖������a/d�ɘӕr��ܾ���vcxo�Ŀ��ƣ��ɘӕr�ƫ���ɲɘӕr�ͬ�����ֹ�Ӌ�õ���a/d�D(zhu��n)�Q��Ĕ�(sh��)��(j��)һ·��agc�z�yȥ���Ƹ��l�^��ݔ������һ·��(j��ng)�^r/c׃�Q��fft����Ҫ�ă�·��̓����(sh��)��(j��)��̖���r�gͬ�����ֹ�Ӌ�õ�һ���r���̖��ͬ���^�������Եع�Ӌ�����հl(f��)�l�ʲ�һ�¶�������lƫ����(j��ng)�^fft׃�Q���l��ͬ����Ԫ����fft�Ĵ���λ�ã�У�������lƫ�Ĕ�(sh��)��(j��)��У����Ĕ�(sh��)��(j��)��(j��ng)�^�ŵ���Ӌ���õ���ǰ���r���ŵ�푑�����(j��ng)�^�ŵ�����̎���������ŵ�����˥���Ӱ푣�Ȼ���ٽ�(j��ng)�^��ӳ��ܛ�ЛQ�g�a�ͽ�_��Ȼ�����l��̖�����ŵ���a����a�������M����Դ��a�����l�C�ϣ����(j��ng)d/a߀ԭ��ģ�M���l?

�D1 ���ՙCԭ����D
2 �������O(sh��)Ӌ˼·
dab���ՙC��Ҫ�ɔ�(sh��)����׃�l��ͬ����ofdm���{(di��o)��viterbi�g�a�Ĵ֘�(g��u)�ɡ�
��(sh��)����׃�l���ǰ�adcݔ�������l��(sh��)����̖׃?y��u)�?sh��)�ֻ�����̖��Ҳ�����ڔ�(sh��)���ό��F(xi��n)�l�V���°��ƣ���Ҫ����ϣ������׃�Q���l�V�°��Ƽ����ɘӵȡ�
ͬ�����ְ����ܰ�����̖���rͬ�����d���l��ͬ���Ͳɘӕr��l��ͬ������fft�����Է֞�r��ͬ�����l��ͬ���ɲ��֡�
ofdm���{(di��o)����fft�Ͳ�ֽ��{(di��o)�ȣ���(j��ng)fft�Ͳ�ֽ��{(di��o)��Ĕ�(sh��)��(j��)�ٽ�(j��ng)�^�l��⽻�����M��qpsk��ӳ�估�������ͽo���m(x��)viterbi�g�a���M��ܛ�ЛQ�g�a��
��ofdm���{(di��o)�́��Ĕ�(sh��)��(j��)��ȡ������Ϣ�ŵ���fic����(sh��)��(j��)�M�н��տs��viterbi�g�a����_���õ��ͺϽY(ji��)��(g��u)��Ϣ��mci����������mci�����I(y��)���ŵ���msc����(sh��)��(j��)�M���g�a��
dab���ՙCӲ���·�O(sh��)Ӌ
1 �����Y(ji��)��(g��u)��D
����(j��)��dab���ՙC�M�ɲ��ֵķ����������O(sh��)Ӌ����fpga+dsp���O(sh��)Ӌ������dab���ՙC�����ĽY(ji��)��(g��u)��D��D2��ʾ��dab��̖���쾀���պ��M����l�^���֣��x��������l�ʉK��Ȼ���x���ĸ��l��̖������l����׃?y��u)������l�ʞ�38.912mhz��������1.536 mhz�����l��̖�����l��̖�V���o�õ��l�V���ֺ��ٽ�(j��ng)�l��׃�Q�͞V����׃?y��u)������l�ʞ�2.048 mhz��������1.536mhz�Ļ�����̖��Ȼ���M��adc���ɘ����ʞ�8.192mhz���D(zhu��n)�Q�ɔ�(sh��)����̖���M��fpga��fpga��ɲ����D(zhu��n)�Q��ͬ���ͽ��{(di��o)�� �Լ�vcxo����Ŀ����·�ȡ�̎����Ĕ�(sh��)��(j��)�M��dsp��dsp�ⲿ�r犞�24.5mhz������dsp���M��4���l��������100mhz��dsp����ɽ⽻����viterbi�g�a����_�Լ����l��a�����(sh��)��(j��)������dac���֏ͳ�ԭʼģ�M��̖���������ȼ����� ��

�D2 ���ՙC�ĽY(ji��)��(g��u)��D
2 �������x��
�������x��Ҫ���ڝM��ϵ�y(t��ng)�������r������ʹ�ɱ���ͣ�������С���O(sh��)Ӌ�����������{(di��o)ԇ������Ҫȫ����оƬ���\���ٶȡ��r��Ӳ���YԴ���\�㾫�ȡ������Լ�оƬ�ķ��b��ʽ���|(zh��)���˜ʡ���؛��r���������ڵȡ��C�Ͽ��]���ώ������أ������O(sh��)Ӌ��adc�x��tlv5535��dac�x��akm4352��fpga�x��ep1s40��dsp�x��tms320vc5510��
tlv5535��һ�����܃�(y��u)����8λadc������35msps�IJɘ����ʣ�3.3v���Դ��늣�������ֻ��90mw��ģ�Mݔ�뎧���_600mhz�����m�ϱ��O(sh��)Ӌ��akm4352�Ƿdz��m�ϱ�yʽ���l�O(sh��)���dac������20khz���ɘ�����8��50khz������늉���1.8��3.6v��ͨ������ֻ�С�0.06db���莧˥�p�_43db�����ܷdz���(y��u)����tms320vc5510��ti��˾��һ������ܡ�����dsp�������кܸߵĴ��a��(zh��)��Ч�ʣ������ָ���(zh��)���ٶȿ��_800mips���pmac�Y(ji��)��(g��u)�����O(sh��)�õ�ָ����پ��_�惦��������24kb��Ƭ��ram��160k��16b������߀��3�M��ͨ�����_���пںͿɾ��̵Ĕ�(sh��)���i��h(hu��n)�l(f��)�����ȣ�i/o늉� 3.3v����(n��i)��늉�1.6v��ep1s40��altera��˾stratixϵ��fpga�����зdz��ߵă�(n��i)�����ܡ��惦�������ܘ�(g��u)Ч�ʣ��ṩ�ˌ��õĹ������ڕr犹����͔�(sh��)����̖̎�푪�ü���ֺ͆ζ�i/o�˜ʣ�����߀����Ƭ��(n��i)ƥ����h��ϵ�y(t��ng)���������������S���ҹ����^С��ep1s40��Ƭ��(n��i)�YԴҲ���ԝM�㱾�O(sh��)Ӌ���衣
3 ��Ҫģ�K���·�O(sh��)Ӌ
adc�cfpga���B������fpga��(n��i)��ɲ���׃�Q���g�a�·Ҳ��fpga����ɡ�fpga�cadc�g���B�Ӱ�����(sh��)��(j��)���͕r犾���adc�ĕr���fpga���ṩ����(sh��)��(j��)���͕r犾����cfpga��i/o���_ֱ�����B���ɣ���D3��ʾ��

�D3 adc�cfpga�B��ԭ��D
dspͨ�^�������п��cdac�B�ӣ���D4��ʾ��dacݔ����ģ�M��̖��(j��ng)�V�����ֱ��ݔ���Z����̖��

�D4 dsp�cdac�B��ԭ��D
�F(xi��n)��ĸ���dsp��(n��i)�治�ٻ���flash�����Dz��ô�ȡ�ٶȸ����ram��dsp��늺����(n��i)��ram�еij���͔�(sh��)��(j��)��ȫ���Gʧ��������Ó�x�������ĭh(hu��n)���У�dspоƬÿ����늺������e�����ⲿ�惦�^(q��)�Ĉ�(zh��)�д��aͨ�^ij�N��ʽ���Ƶ���(n��i)���惦�^(q��)�����Ԅӈ�(zh��)�С����õ����e��ʽ�в������e���������e�����C�ӿڣ�hpi�����e��i/o���e��hpi���e��Ҫ��һ�����C�M�и��A���mȻ����ͨ�^�@�����C��dsp��(n��i)��������r�M�бO(ji��n)�أ����·���s���ɱ��ߣ��������e���a���d�ٶ�����i/o���e�Hռ��һ���˿ڵ�ַ�����a���d�ٶȿ죬���·���s���ɱ��ߣ��������e���d�ٶȿ죬�mȻ��Ҫռ��dsp��(sh��)��(j��)�^(q��)�IJ��ֵ�ַ�����o����������ӿ�оƬ���·���Ρ������ti��˾��5000ϵ��dsp�еõ��ˏV�����ã������O(sh��)ӋҲ�Dz��ò������e���c���y(t��ng)��eeprom��ȣ�flash����֧���ھ������Ҳ����Δ�(sh��)�ࡢ�ٶȿ졢���ĵ͡�������̓r������ȃ�(y��u)�c��Ŀǰ�ںܶ�flashоƬ����3.3v���Դ��늣��cdsp�B�ӕr�o횲����ƽ�D(zhu��n)�QоƬ������·�B�Ӻ��Ρ���ϵ�y(t��ng)���̕r������ϵ�y(t��ng)������dspֱ�ӌ�����flash���̣���(ji��)ʡ�˾��������M�ú��_�l(f��)�r�g��ʹ��dsp��(zh��)�д��a�����ھ����¡��D5���ⲿ����(sh��)��(j��)�惦��flash���·�B�ӡ�

�D5 �ⲿ����(sh��)��(j��)�惦��flash���·�B��
fpga�cdspͨ�^mcbsp��gpio��emif��ehpi�����B���ӿڷN࣬���ڸ���(j��)��Ҫ�`��ʹ�á�fpga��(n��i)�ij���͔�(sh��)��(j��)��늺�Ҳ��ȫ���Gʧ�����Ԟ�������ˌ�������оƬepc16����늺��Ԅӌ��������d��fpga�У��������á�
���Y(ji��)
���˷����{(di��o)ԇ�������O(sh��)Ӌʮ���`�����ϵ�y(t��ng)�YԴҲ���^�࣬���H���Ԍ��F(xi��n)ģʽ1���������NģʽҲ�����ڴ�Ӳ��ƽ�_�ό��F(xi��n)���Á��惦����͔�(sh��)��(j��)��flash�ȿ�����fpga���x����Ҳ������dsp���x����dsp��fpga�քe����jtag���d���������d����͙z�yоƬ��dsp߀�B��rs232�����ڰl(f��)������ָ���Լ��O(ji��n)��dsp��(n��i)����r��fic��a��ɺ���M��dab/dmb�ĘI(y��)���x������(j��)�x��I(y��)�յIJ�ͬ�M�в�ͬ��̎����քe�a(ch��n)�����͈D����̖�����քe�����Ȼ�Һ���@ʾ��ݔ����
�D14��3��3�o����C54Xϵ��DSP�ă�(n��i)���Y(ji��)��(g��u)��
�F(xi��n)�Y(ji��)�ϱ�14��2��5���D14��3��3�Լ�C5000ϵ�е��Ñ��փԁ��f��ԓϵ��DSP��
���c

C54X�ĕr��l�ʞ�40��50��66��80MHz�������ģ��r����ڞ�25��20��15��12��5ns���\��
������40��50��66��80MIPS��Ƭ��RAM��5��256ǧ��֮����Ƭ��ROM��2��48ǧ��֮
�g���Sϵ�Ѓ�(n��i)����̖��ͬ����ͬ��RAM�ַ��p�L��RAM(DARAM)�͆��L��RAM
(SARAM)��
C54X��16bit���cDSP����(n��i)�����������²�����
(1)һ��40bit��ALU��
(2)�ɂ�40bit���ۼ���A��B��
(3)һ��17��17bit�ij˷���������һ��40bit�ļӷ���(adder)һ����һ����ָ����
�ڃ�(n��i)��ɶ��M���a�a�ij˷��\�㣻
(4)Ͱ��(barrel)��λ������ݔ���B�ӵ�40bit���ۼ�����(sh��)��(j��)�惦��(CB��DB)��
40bit��ݔ���B�ӵ�ALU��(sh��)��(j��)�惦��(EB)�����Ɍ�ݔ�딵(sh��)��(j��)��0~31bit�����ƣ�����
O��16bit�����ƣ�
(5)��COMP��TRN��TC�M�ɵı��^���x��ʹ惦��Ԫ(compare��select��and store
unit��CSSU)��
(6)ָ��(sh��)���a��(EXP)������֧��ָ��(sh��)EXP�Ŀ����\�㣻
(7)8��16bitͨ�üĴ�����
C54X���ö࿂���Y(ji��)��(g��u)����(n��i)������8�M������4�M�����(sh��)��(j��)������4�M���ַ��
�����D14��3��3��PB����������͏ij���惦������ָ����a��������(sh��)��PAB���
���ַ������CB��DB��EB�����M��(sh��)��(j��)�������B�ӵ����N��������CPU����(sh��)��(j��)�惦���ȡ�
CAB��DAB��EAB���@���M��(sh��)��(j��)���������ĵ�ַ������CB��DB���͏Ĕ�(sh��)��(j��)�惦���x��
�Ĕ�(sh��)��EB���͌��뵽��(sh��)��(j��)�惦���Ĕ�(sh��)��Sign ctr���̖��������C54X���Ãɂ��o����
������Ԫ(ARAU0��ARAUl)�چ����ڃ�(n��i)�a(ch��n)���ɂ���(sh��)��(j��)�惦���ĵ�ַ��
C54X�Ĵ֮a(ch��n)Ʒ��I��O�ڵĹ�늞�3��3V��CPU�˵Ĺ��Ҳ��3��3V���½��Ƴ�
��C5402��C5409��C5401�ĺ˲���1��8V��늣�I��O��һ����3����3V��늡���늉���늿�
����ġ�
���P(gu��n)C54X�Y(ji��)��(g��u)�c���ܵ�Ԕ����(n��i)��Ո�����īI[6]��E17]��
2��TMS320C55X�������c�Y(ji��)��(g��u)���c
C55Xϵ���Ǻ�C64Xϵ����2000���ͬ�r�Ƴ�������DSP�a(ch��n)Ʒ��C55�ǽ�����
C54Ӳ���Y(ji��)��(g��u)�Ļ��A(ch��)�ϵģ����Ҳ��16bit�Ķ��cDSP��ͬ�r��ܛ����Ҳ��C54���ݡ�
C55��������c�������DSP������ͬ�r�Mһ�������˹��ġ�C55�Ĺ��Ŀɵ���
0��05mW��MIPS��ԓϵ�е�һ���a(ch��n)ƷC5510�ĕr犞�160MHz���\��������320MIPS����
ָ��Ҋ��14��2��5���M�����(n��i)�˵Ĺ��Ҳ��C5402�ǘӞ�1��8V��I��O�ڞ�3��3V����C55��
�O(sh��)Ӌ��(����Ӳ����ܛ��)��ȡ��һϵ�д�ʩ����������Ҫ�������M���Ԅ��Դ�������g(sh��)��
ԓоƬ��CPU�����е�����O(sh��)�䡢�惦����С�CPU�ĸ�����Ԫ�M���B�m(x��)�ıO(ji��n)ҕ�����r
�������IJ��քtֹͣ���乩늡�
TI��˾����C5000ϵ��DSP��λ��ͨ���I(l��ng)��đ��ã��e�DZ�yʽͨ�Ź��ߵđ�
�á�C5402���e��C55X���Ƴ��������֙C����(sh��)�����C�����˔�(sh��)������(PDA)�Ƿdz��m��
�ġ��S�������t(y��)�W���̵İl(f��)չ��DSPҲ���ڴ����t(y��)���x���ИI(y��)�������ܡ���yʽ�t(y��)��
�x������C5000ϵ�е�����֮��
DMR-CP01�����W(w��ng)�j�Ԓ�C
VOIP�����W(w��ng)�j�Ԓ�CCP01�I�P�^(q��)�O(sh��)��.DOCVOIP�����W(w��ng)�j�Ԓ�C�������1.JPG
VOIP�����W(w��ng)�j�Ԓ�C�������2.JPG
- VOIP�����W(w��ng)�j�Ԓ�C����
- �Ј����ϣ����ڵ^(q��)��Ψһ��OEM������� ��
- ���g(sh��)֧�֣��ṩ�L�ڵļ��g(sh��)��ԃ�����g(sh��)���ա�ܛӲ�����M�ȡ�
- �ṩ���g(sh��)�Y�ϣ�VOIP�W(w��ng)�j�Ԓ�Cԭ��D��VOIP�W(w��ng)�j�Ԓ�CPCB�·��D������VOIP�W(w��ng)�j�Ԓ�C�·���Ԫ������Ŀ����
- �ṩ��Ҫ��VOIP�W(w��ng)�j�Ԓ�C������оƬ�P��CM5000�IJ�ُ������VOIP�W(w��ng)�j�Ԓ�C���^�����b��VOIP�W(w��ng)�j�Ԓ�C�f������VOIP�W(w��ng)�j�Ԓ�Cģ���ƾ߲�ُ������
- VOIP�����W(w��ng)�j�Ԓ�C���İ�ʹ���f����.DOC
- VOIP�����W(w��ng)�j�Ԓ�CӢ�İ�ʹ���f����.DOC
- VOIP�����W(w��ng)�j�Ԓ�C���İ�ʹ���f����.PDF
- VOIP�����W(w��ng)�j�Ԓ�CӢ�İ�ʹ���f����.PDF
- VOIP�����W(w��ng)�j�Ԓ�C��������f(xi��)�h.PDF
![]()

DMR-CN02�����W(w��ng)�j�Ԓ�C
VOIP�����W(w��ng)�j�Ԓ�C�������1.JPG
VOIP�����W(w��ng)�j�Ԓ�C�������2.JPG
VOIP�W(w��ng)�j�Ԓ�C������
VOIP�W(w��ng)�j�Ԓ��ָ����Internet���Ԓ�Ľ����O(sh��)�䡣�b�нK���O(sh��)��ęC��(g��u)�gͨԒͨ�^Internet��ɣ�ֻ���ϾW(w��ng)�M���]���Ԓ�M���ɞ��Ñ���(ji��)�s�������L;ͨӍ�M�ã��Ԓ���|(zh��)�������������S����䣬�����cӋ��C�B�ӣ�ʹͨԒ�������κΕr�����M�У��dz��m����I(y��)�k���ͼ�ͥʹ�á�
- VOIP�W(w��ng)�j�Ԓ�C�������c��
- ֧��SIP2.0��TCP/UDP/IP��RTP/RTCP��HTTP��ICMP��ARP/RARP��DNS��DHCP��NTP��PPPoE��TFTP�ȅf(xi��)�h��
- �c���H�Ј��϶�ҏS�̵�ͬa(ch��n)Ʒ���ݡ�
- ֧�ָ��N�Z�����a���H�˜ʣ�G.723.1 ��G.729A/B��G.728��G.726��G.711(A-law/U-law), iLBC, G.722���l���a��
- ֧��ͨԒ�z�y(VAD)��������ģ�M(CNG)���Ԅ�����(AGC)���ͻ�����(G.168)��֧�ָ��N���ܼ��J�C�˜�(BASIC, DIGEST, MD5��MD5-sess�㷨)��
- ֧��ISO�W(w��ng)�j�Y(ji��)��(g��u)�ڶ��Ӻ͵�����QoS (802.1Q VLAN, 802.1p, DiffServ, MPLS)�� ֧��IETF STUN (������/NAT��ȫ��) �˜ʼ��Ј��ϸ��N�F(xi��n)�з�����/NAT�a(ch��n)Ʒ���Ñ��o횸Ąӷ������O(sh��)�á�
- ֧���h��ȫ�Ԅ��O(sh��)���������Ч���F(xi��n)�Ñ��ˡ��㡱�O(sh��)�á����弴�á�˽�W(w��ng)�����Լ�ܛ���Ԅ���������ͨ�^�Ԓ�I�P��Web��������P(gu��n)���ܾW(w��ng)��ϵ�y(t��ng)����ظ������ü�������
- �ྀͬ�rͨԒ��ռ�Î����YԴ�O�٣�ֻ��ռ��һ�l��ͨ�������֧��16�l��ͬ�r�������������·�ɹ�������������ʽ�ϾW(w��ng)���tֻ��ռ�ü�����/���Q�C��һ���˿ڡ�
- �ܴ�ʹ�÷��㡣
- ���弴�ã����b���㣬�o���׃�F(xi��n)��ϵ�y(t��ng)��
- �L;�ԒԒ�M���͡�
- ��Ԓ���|(zh��)����������
- ֧��PBX���̿ؽ��Q�C����
- ���_�K�˿ɯB��ʹ�ã�����Uչ��
- �֙C��(g��u)֮�g�ɶ�D(zhu��n)�ӣ��ͨԒ��
- VOIP�W(w��ng)�j�Ԓ�Cϵ�y(t��ng)������
- � Ԓ �������Ԓ���п��Բ��ҡ����ӻ�h���Ԓ̖�a�����ɴ惦 100�lӛ䛡�
- ͨԒӛ䛣��@ʾ���Ё�늣��@ʾ�����ѓ�̖�a���h��ͨԒӛ䛡����ӛ䛡���̖ӛ䛡�
- ���ٓ�̖�����O(sh��)�á��h�����ٓ�̖��ʹ�ÿ��ٓ�̖����ֻ��ܿ��ٓ�̖��(sh��)�� (0~9)��ӡ�#���I���ɣ������O(sh��)��10���ٓ�̖�a��
- �Ԅӓ�̖�����I�^(q��)ݔ���Ԓ̖�a�r����ݔ��#���I���O(sh��)���r�g����ϵ�y(t��ng)�Ԅӓ�̖���Ɍ��Ԅӓ�̖�r�g�O(sh��)�Þ�3~9��犡�
- �A �� ̖����̖������ԒͲ�������I��IP�Ԓ�_ʼ��̖��
- �ГQ�������ГQ���I����IPͨԒ��B(t��i)�ГQ����̖��B(t��i)��
- �Ԅӽ� ���O(sh��)���Ԅӽ� ���ܣ��Ñ����ԏ�IP�Ԓ��PSTN�Ԓ�ܻؓ��PSTN�Ԓ��IP�Ԓ�ؓܡ��@헹��ܿ�������FXO�ӿڵ�IP�Ԓ��ʹ�á�
- ����D(zhu��n)�ӣ��O(sh��)��Ҫ�D(zhu��n)�ӵ��Ԓ̖�a�������N��ʽ���x�����Ё���D(zhu��n)�ӣ�ռ���r����D(zhu��n)�ӣ��o�˽� �r����D(zhu��n)�ӡ�
- ���O�����푺����Ԅӽ� ���ܡ��@헹��ܿ�������FXO�ӿڵ�IP�Ԓ��ʹ�á�
- �ܽӁ�늣����Ԓ�O(sh��)�Þ�ܽӠ�B(t��i)���оܽ����Ё�늺�һ�Εr�g��(n��i)�ܽ����Ё�늿��x��
- ���еȴ����Ñ�����@֪�Ё�늕r���O(sh��)�ú��еȴ�����ͨԒ�r�����Ԓ����������ГQ���I�������Ԓ�������I�Ɍ��F(xi��n)���Ԓ�g�ГQ��
- ���ڕr�g���O(sh��)�����ڕr�g��
- �r�g�O(sh��)��������ͨ�^�O(sh��)����һ��ڶ��W(w��ng)�j�r�g��������IP��ַ���@ȡ���ڕr�g��Ϣ��ͬ�ӿ��Ը���(j��)�����ڵ�λ���O(sh��)���r�^(q��)���ٴ��{(di��o)������r�g��
- �����{(di��o)����ԒͲ�����{(di��o)���� Ͳ�����{(di��o)��������ԒͲ�����{(di��o)����
- ��O(sh��)�������{(di��o)����������x��
- ͨԒ�������������������Iʹ��ǰ�Ԓ����һ�Εr�g����࣬�ٴΰ����������I���^�m(x��)ͨԒ��
- ����ͨԒ����Ҫ�M������ͨԒ�����ȴ��Ԓ�o��һ�����Ԓ��ͨ���ГQ���I�� ����̖������Ԓ�o�ڶ�������ͨ���ٰ����ГQ���I��
- �����D(zhu��n)�ӣ�֧�����N�����D(zhu��n)��
VOIP�W(w��ng)�j�Ԓ�C��עһ��CM5000оƬ����
CM5000��һ���߶ȼ��ɵ�VoIP��Q��������������32λRISC CPU��DSP��2��������̫�W(w��ng)��ַ��CM5000��Ч������VoIP�W(w��ng)�P(gu��n)��IP�Ԓ�ɱ������á�
CM5000���ɵ�32λRISC CPU���l�ʞ�125MHz����(n��i)����4K�ֹ�(ji��)��ָʾ���漰4K�ֹ�(ji��)�Ĕ�(sh��)��(j��)���档��֧��ϵ�y(t��ng)�������W(w��ng)�j�������f(xi��)�h�����������ó���
CM5000���ɵ�16λFix-Point DSP���l�ʞ�125MHz��֧��32K��24�Ŀɾ��̴惦����16K��16��ϵ��(sh��)�惦����15K��16�Ĕ�(sh��)��(j��)�惦�������ṩ2�����ж˿�֧��2����ͨ����DSP֧�ֶ����sģʽ��G.711��G.723.1��G.729A��G.729B����������������N��ͨ�Ԓ���g(sh��)��
CM5000�ṩ2��10/100M������̫�W(w��ng)��ַ֧��ȫ/���p��ģʽ���˿ڻ���VLAN��MII�ӿں�2K�ֹ�(ji��)��FIFO������������Ñ���ͨ�^MII�ӿ��c�ⲿPHY����̫�W(w��ng)���QоƬ��(g��u)��VoIP�W(w��ng)�P(gu��n)��IP�Ԓ��
��CM5000����IP�ԒоƬ���Õr��Ҳ�ṩ��LCD���ơ��I�^(q��)��UART���нӿںͶ�����ͨI/O�ӿڵ�֧��
�a(ch��n)Ʒ��B��
VoIP��Q������CM5000������32λRISC CPU��DSP��2��������̫�W(w��ng)��ַ��CM5000����Ч������VoIP�W(w��ng)�P(gu��n)��IP�Ԓ�ɱ������á�
![]()
CM5000оƬ����VOIP�W(w��ng)�j�Ԓ�C����ԭ��
RISC CPU
* 4Kbytes of direct mapped instruction cache
* 4Kbytes of direct mapped data cache with write-through policy
* Memory Controller:Flash/SDRAM
* 125MHz internal system clock
* JTAG support
16-bit fixed-point DSP
* Program SRAM 32K*24
* Coefficient SRAM 16K*16
* Data SRAM 15K*16
* Two Serial Port Interfaces
* DSP clock speed runs at 125MHz
Two 10/100 MACs
* IEEE802.3/802.3u compliant
* Half/Full duplex operation
* VLAN support
* MII interface to external PHY
* Scatter and gather transmit/receive DMA
* 4KB transmit/receive FIFO
�S����(sh��)����̖̎���� (DSP) �đ��÷��������U������M����ܛ��ģ�K���������L���������ṩ�ĬF(xi��n)���㷨�ڻ����������܉�푑��������������㷨ʹϵ�y(t��ng)�_���̲������M�������O(sh��)Ӌ��Ҫ��ܛ�����ܣ��Ķ��܉���졢�����r�،�ϵ�y(t��ng)�c����ܼ��ɡ���ˣ��������㷨�� DSP ϵ�y(t��ng)�_�l(f��)�аl(f��)�]���dz���Ҫ�����á�
����ʹ�M��ܛ�����������������횾߂䱣�C�M�����a�����ԡ�һ���Ժͱ�y�ԵĘ˜ʡ�DSP�S���J�R���������������˹�����ͬ�㷨�c����֮�g�ӿڵ��㷨�˜ʡ������˜ʲ��Ǟ��˱��C��Ч��ʩ��ᘌ����a��С�����Լ����ܶ��x������㷨�Ĺ�������ϵ�y(t��ng)�������M�еġ����˜������ģ��t���ṩ�_���㷨֮�g��f(xi��)����һ��Ҏ(gu��)�t��ʹ�������p�ɵ��M���u����Ȼ����ϵ�y(t��ng)�h(hu��n)�����M�м��ɡ�
�㷨�˜ʵ���Դ
20���o90������ڣ��㷨�˜ʵ�������u�@�F(xi��n)�������˕r���鏊��� DSP ���F(xi��n)�ˣ����֧��һ���㷨�Ķ�ͨ��������ͬһ DSP �ϵĶ����㷨���M�����ڵ� DSP ���܃H�����Z�����a���ȣ�������� TI TMS320C5000 ƽ�_�� DSP �t�܉�̎����C�Ԓ�����������(sh��)��̎��朣������a�����lУ�����ز������ȡ��T����� TMS320C6000ƽ�_������ DSP���t�܉��_�l(f��) DSL ������ҕ�l�������������چ��O(sh��)����Ҫ����ИO�߶�ͨ�����ܵ�ϵ�y(t��ng)��
���ìF(xi��n)�и��ߌӴε����ܣ��S�����d��̖̎��˜ʲ���ӿ�F(xi��n)������ JPEG��MPEG���ҕ���h���o���Ԓ�Լ��{(di��o)�ƽ��{(di��o)���c������M�ȡ��_�l(f��)���_ʼ��(chu��ng)��������׃?n��i)΄յĄӑB(t��i)ϵ�y(t��ng)��������һ����� DSP �ľ��й̶����ܵ��o�B(t��i)ϵ�y(t��ng)������ϵ�y(t��ng)���aҎ(gu��)ģҲ�_ʼ���������������m�����Ͷ��ϵ�y(t��ng)�ď��s�Զ���������ӡ�
DSP ϵ�y(t��ng)�_�l(f��)��ʼ�Kȱ�ٽ�(j��ng)��S��������������̖̎��֪�R�� DSP ����T��Ŀǰ���@Щ�_�l(f��)�̂��_ʼ���ɸ�����s��ϵ�y(t��ng)��һЩ�����M�� DSP �I(l��ng)��������_�l(f��)�̄t���_ʼ�M������� DSP �O(sh��)Ӌ���������L�ĘI(y��)��ϵ�y(t��ng)�����̌��Ҹ��N�����팢������s�����O(sh��)�����������������؏��^�O(sh��)Ӌ����ܛ�������\���ǣ�һЩ�߂�I(y��)��(j��ng)��Cܛ�����g(sh��)���_�l(f��)���J�R���µ��Ј��̙C�����_ʼ���������������֪�R�a(ch��n)��(qu��n)�������㷨��ϵ�y(t��ng)�����̌��ĵ�����ُ�I"�ں���"Ŀ�˴��a����������d��ϵ�y(t��ng)�У��Թ�(ji��)ʡ���F���_�l(f��)�r�g�������@���Ǽ��O(sh��)�Ĺ��������ˡ�
Ȼ�����ڌ��`�����鲢�����ֱ�ӡ��������_�l(f��)�̳����ٶ�DSP�÷����Ա�ʹ���㷨�M���ܾ��������@���������Ч������ˣ�һ���㷨������Ҫռ�����Ѓ�(n��i)�棬�ں��L�ĕr�g�н��ó��F(xi��n)�Д࣬����ȫ���ƺ��ġ����⣬ϵ�y(t��ng)�����̿��ܟo���˽��_�l(f��)�̵����ȼٶ���ʲô����鲻���ڽy(t��ng)һ�ķ���ָ���㷨���YԴҪ���c����Ч����
�@Ȼ��������������ٶ���Ԓ����ô�ɷN���N�㷨�Ͳ����ڶ��ϵ�y(t��ng)�к�ƽ��̎���@�ӵĆ��}������Դ���a�M�����O(sh��)Ӌ�r�����ஔ���y�������D����Ŀ�˴��a��ϵ�y(t��ng)�_�l(f��)�̌���׃�㷨�o�ܞ��������ң�����㷨���Բ�ͬ�ĵ���������������ˣ��������̌����R���������y�}�Լ����ɱ�����ָժ��
��20���o90���ĩ��ֹ�������@��������㷨�����О�Ҏ(gu��)�t����ô DSP �_�l(f��)��ͣ����ǰ����ˣ�DSP �S���_ʼ�l(f��)���@�NҎ(gu��)�t�����侎���������ܛ���_�l(f��)�̱����ѭ�Ę˜ʴ��a���Ա㱣�C�㷨�ļ����ԡ��M���@Щ�˜��Ǿ������Й�(qu��n)�ģ���������������ͬ��Ŀ�ˣ������S��Ҏ(gu��)�t����һ�ӵġ�����ijЩҎ(gu��)�t��ӳ��Ӳ����ʩ�����҃Hᘌ�ijЩ���w�S�̣���ˌ����Й�(qu��n)�����ǘI(y��)��˜��M�б��������⣬���˜ʳ��F(xi��n)�r���S�̞��˸��� DSP ���_�l(f��)��������푑����r���������nj����}���o���L�ĘI(y��)��˜ʻ��M�́���Q��
ʾ���˜�
��������Ę˜�֮һ�� TI �� TMS320 DSP Algorithm Standard?��Ҳ�Q��XDAIS��TI �Ƴ���ԓ�˜������� eXpressDSP? ܛ����(zh��n)�ԵĻ���Ԫ�أ���ͬ�r�Ƴ��ˌ�ʩ��(n��i)�ˡ������_�l(f��)�h(hu��n)�� (IDE) ���������W(w��ng)�j���@�����㷨�˜ʻ����� DSP ܛ���_�l(f��)�аl(f��)�]�P(gu��n)�I�����á�TMS320 Algorithm Standard �Ǹ��N DSP �㷨�˜ʵ�һ��ʾ���������������S���Ƴ���ijЩ�˜ʵ�һ��ģ�͡�
XDAIS ���� TMS320 DSP ��ܛ���ܘ�(g��u)���A(ch��)֮�Ͻ��������ġ��D1�@ʾ�� DSP ϵ�y(t��ng)�ĽM����ʽ���@�Ӻ��Δ�(sh��)��(j��)�������㷨�� I/O �����Լ��Ӻ����\�Еr�h(hu��n)���з��x�������D2�@ʾ�� XpressDSP �h(hu��n)�����㷨�����\�еı�ϵ���¼��� <!-- �D1. XDAIS �c DSP ϵ�y(t��ng) �D2. XDAIS �㷨�¼� -->
XDAIS �㷨Ҏ(gu��)�t
XDAIS Ҏ(gu��)�t�����ĽM���߂������У�C���Ա��C���Ϙ˜ʡ�
���R�Ծ���Ҏ(gu��)�t�����MҎ(gu��)�t���������ڼӏ��㷨�ı�y�ԡ����A�y�Լ������ԡ����ڴ����(sh��) DSP ϵ�y(t��ng)�\���� C �h(hu��n)���У����플ӵ��㷨�������C���{(di��o)�á��㷨���øɔ_���ó�����\�Еr��B(t��i)�����Ҵ��a����ړ�ռʽ�h(hu��n)�����M��������֧�ֶ���ͨ������회������������Ĵ惦���cȫ��׃���M�б��o�����д��a���ñ����ȫ���ٶ�λ�����ò���Ӳ���a�惦����ַ����t���ɔ_�������a�������YԴ������ϵ�y(t��ng)����������㷨����ֱ���L�����O(sh��)��
ȡ�������x���������Ҫ�Ԇ�һ���Ʒ����M��ij헹�����Ԓ��ԓ�˜�ָ���ˑ��ڸ��N��ͬ�����в��úηN�������ͺ���ͨ��Ҏ(gu��)ָ������·�ϑ�����߀�����У�������������_ͻ����̖���������ѭ DSP/BIOS? Ҏ(gu��)�t���@�� TMS320 DSP ���õČ��r��(n��i)�ˡ�����⌢���a��ֲ����ͬ����ϵ�y(t��ng)�h(hu��n)���Еr�l(f��)���_ͻ���㷨��횷��b����ѭ�y(t��ng)һ����Ҏ(gu��)�t�ęn���ļ��С����ʹ�ⲿ���÷��ρ�Դ����C�\��֧�֎캯��(sh��)���������� eXpressDSP ��ģ�K���㷨������횸���(j��)ָ���ij����{(di��o)�ò��h����������������܉������M���ٶ�λ���� C6000? ƽ�_���ԣ��㷨�������֧����С������ֹ�(ji��)�����Ãɂ���֧�֣��Ա��ϵ�y(t��ng)�_�l(f��)���ṩ�x��
�YԴ�����������㷨һ����^؝�������ұ��ʹ����Թ�������˱��Mλ��ԓ�˜ʵĺ��ġ��F(xi��n)��ÿ���㷨�����ˏ��ƵĴ惦���������棬���������㷨��������O(sh��)Ӌ�rһ�΅f(xi��)�{(di��o)�����\�Еr�����f(xi��)�{(di��o)ʹ�ô惦������Ҏ(gu��)�t�m�����ⲿ����(n��i)���惦�����Լ� DMA ͨ�������O(sh��)��������ͬ���ƿ��һ���ռ����д惦��Ո���S�����㷨����惦�����㷨���ܲ��ܫ@����ȫ��Ո�����ÿ���܉��ڸ���Ո���g�M�кܺõ��Д࣬����(y��u)������ϵ�y(t��ng)�YԴ��
�y(t��ng)һҎ(gu��)�������MҎ(gu��)�t������ϵ�y(t��ng)�����̺����㷨���u������ϵ�y(t��ng)�еļ����ԡ����еļ������㷨��횱��F(xi��n)�����r���Д���ݔ�r�g�������c�����r�Ĉ�(zh��)�У��Լ�����ꇡ��o�B(t��i)�Ͷї��惦��Ҫ��ȷ�������c�����磬�㷨�����̿��ܲ����[�m���㷨��ռ��(n��i)�ˎ���犵��Д���ݔ�r�g���F(xi��n)�ڣ���횸���(j��)�Ѵ_���ķ�ʽ���㷨���g(sh��)������ָ����������ݔ�r�gҪ��
У��c eXpressDSP һ�������㷨�_�l(f��)�̲��ܺ��ε��f���M���� TMS320 Algorithm Standard ��Ҫ���_�l(f��)�̱��ͨ�^ TI �� XDAIS һ���Ԝyԇ�������C����ԓ���߿�У���a�Ƿ����Ҏ(gu��)�t�����⣬��������횕���ͬ�����_�l(f��)�㷨�r��ѭ�˘˜�Ҏ(gu��)�������M�����@ЩҪ��r�����������������㷨���� eXpressDSP�����ڏV��������ʹ�ÈD3��ʾ�Ę�־��һ���Թ��߿��m���ڵ������� DSP �͑����Ա�ʹ�������_�l(f��)����ܛ���r���@Щܛ���M�Йz�顣ϵ�y(t��ng)������߀��������ԓ���߱��C����ُ�I�Ĵ��a�ګ@��eXpressDSPһ���ԷQ̖��]�н�(j��ng)�^�ġ� <!-- �D3. eXpressDSP һ���Ԙ�־ -->
XDAIS �İl(f��)չ
XDAIS ��5��ǰ�Ƴ��r����Ҏ(gu��)�t߀����30�l���F(xi��n)����������46�lҎ(gu��)�t���@��ӳ�����˜ʵ�����l(f��)չ������l(f��)չ�����J�桢�ܿصķ�ʽ�M�еġ���Ҏ(gu��)�t�����ӣ��Լ�һЩ�Ąӣ����������cԭ��
��Ӳ������������ijЩҎ(gu��)�t�Ǟ��˺��w�輼�g(sh��)���_�l(f��)�����磬�S������ DMA ���ܼ��ɵ�оƬ�У�XDAIS Ҳ�������µ�Ҏ(gu��)�t�Ժ��w DMA ͨ���ķ��䡣δ����XDAIS߀���ܰ������P(gu��n)Ӳ�����������鹲���YԴʹ�õ�Ҏ(gu��)�t��
���܃�(y��u)�����郞(y��u)�����ܣ�DMAҎ(gu��)�t���M������ӆ���ڴˣ��@ЩҎ(gu��)�tҲչʾ��XDAIS �˜��е���һ��׃���I(l��ng)����������Ҏ(gu��)�t��Q���ش�_ͻ�����һЩ�^�µ�ָ����ᘃA���ڎ����_�l(f��)�̸��õذl(f��)�]ϵ�y(t��ng)��(y��u)�ݡ�
�����I(l��ng)����XDAIS�����ָ�������Ҫ�Ǟ���̎�펧�Д�(sh��)��(j��)�����õĆι���DSP�����Z������ҕ�l�ȡ�������Ķ��ϵ�y(t��ng)�������̎��ͻ�l(f��)��(sh��)��(j��)���� IP ��(sh��)��(j��)��������s���{(di��o)�ƽ��{(di��o)���˜�����ƿ�ܵľ��a���@Щ���õĺ��ĺ�ϵ�y(t��ng)Ҫ���Еr�c�����õIJ�ͬ����XDAIS Ҏ(gu��)�t��횰����ɷN��͵Ĕ�(sh��)��(j��)��������
��һ���]�и�׃�����ԣ�����Ҫ���_�N�������^��ˮƽ����(j��ng)��@ʾ��DSP �͑��c�����������ܲ����^һ���ɂ��ٷ��c�����ܼ��惦���ɔ_���@����ͨ��̎����������һ���^С���_�N�ٷֱȣ�ԓ̎������ͨ�^�Д����(q��)�ӿ����΄գ�����ʮ�������ڃ�(n��i)��ĸ�Ч���á����ǣ�ͨ��ÿ������MIP��DSP���Ƿdz��P(gu��n)�I�ģ���� TI ��Ŭ���� XDAIS �_�N��������������(n��i)��
�㷨�˜ʵĽ���
�M��һֱ��ܛ��Ҏ(gu��)�t��������M����ԃ������Щ����������������ܷ���㷨�˜��Ы@���DZ��Б��ɑB(t��i)�ȵġ��S����������㷨���_�l(f��)������ȫ���������ĘI(y��)�գ����gӭ DSP �S�̅��c���J���@��һ�N�ɔ_�����⣬����ʹ�㷨�����µĘ˜ʣ�һЩ�؏����Dz��ɱ���ģ����������t�����Г������J���Dz���Ҫؓ���Ĺ��������ң����c�˜����P(gu��n)���_�N���PҲ�з���������
�c�������γɌ��ȵ��ǣ�DSP ϵ�y(t��ng)�����̎��������˜ʱ�ʾ�gӭ��һЩ�^����DSP �_�l(f��)���ѽ�(j��ng)��Ŭ������������Ҏ(gu��)�t���� DSP �˜ʵĵ�����(ji��)ʡ�������Ĺ�����ϵ�y(t��ng)������߀�J�R�����c�㷨�˜����P(gu��n)�������_�N����������������r�g���M�c�韩���@�N��(ji��)�s�ărֵ����^����������횽��ܵĴ惦���c���ܙ�(qu��n)�⡣
һ��������Ϥ���@Щ�˜ʣ�DSP ϵ�y(t��ng)�����̾��_ʼҪ���㷨һ���ԣ��@�Ӽ��������Ը�ĵ�����Ҳ���ò��������¡����ˑ������~���_�l(f��)�����ķ�����Ҋ�����F(xi��n)�ˎ����������_�l(f��)һ�����㷨�Ĺ��ߣ��D4��ʾ�� Hyperception Component Wizard ��������һ�����������Ɏ�����(chu��ng)�� XDAIS �㷨�� <!-- �D4. Hyperception Component Wizard -->
���죬�˜��ѵõ��ձ���ܣ��������Ը���㷨�_�l(f��)��Ҳ�Jͬ�˜ʻ�ʹ�ó���ܛ�����̙C������ӡ�����(j��)�˜��M���O(sh��)Ӌ߀��ζ���܉���С��֧�����Ķ���(ji��)ʡ���������_֧��TMS320 Algorithm Standard �����w�F(xi��n)�˜��ж�ô�ɹ���һ��������Ŀǰ������ eXpressDSP �㷨�ĵ������_�l(f��)���_110�����Ҕ�(sh��)��߀�ڲ������ӡ����� DSP �S��Ҳ�J�R���㷨�˜ʵ�����������Ե�ƽ�_�͵������㷨�ṩ�����ƵĮa(ch��n)Ʒ�����ژ˜ʺ��w�˿ɻ������Ծ��̵Ļ������}�������Ҏ(gu��)�t���S��涼�c����Ƴ��Ę˜� TMS320 Algorithm Standard ���ơ�
���d�a(ch��n)�I(y��)
���ϣ�DSP �㷨�˜ʎ�����һ�Nǰ��δ�еć��H�a(ch��n)�I(y��)�����죬ij���^(q��)��ϵ�y(t��ng)�����̿���ͨ�^�W(w��ng)վ����һ���^(q��)�ĵ�����ُ̎�I DSP �㷨��ֻҪԓ�㷨ͨ�^�J�C�������㷨�˜ʣ���ôԓϵ�y(t��ng)�_�l(f��)�̾�֪���˴��a�ڑ��ÿ���п������l(f��)�]���á��� DSP ϵ�y(t��ng)�����̶��ԣ�һ�����㷨�Ѻ����ˌ�������Ŀ�˴��a�M���u�������ɵĹ������Ķ��������_�l(f��)�M�̲��s���ˮa(ch��n)Ʒ���Еr�g ��
�����҂���K�������㷨���F(xi��n)�ژI(y��)���д��ڵĆ��}�����ڌ�����ܛ���M������졢�(q��)�ӳ���(n��i)���Լ�ͨӍ���ȣ��M�И˜ʻ�������ʲô��(y��u)�ݡ�DSP �S�������ڸ��M�F(xi��n)���㷨�˜ʵ�ͬ�r�����ѽ�(j��ng)�ڿ��]���P(gu��n)�������M���Ę˜ʻ������M�ДUչ�Ć��}�ˡ�
�S�� DSP �a(ch��n)�I(y��)�^�m(x��)���@���M��ܛ��ģ���M���_�l(f��)���㷨�˜ʵărֵ��׃��Խ��Խ���@���˜��ṩ��һϵ��Ҏ(gu��)�t������(j��)�O(sh��)Ӌ�����H���@ЩҎ(gu��)�t�܉��C�M�����κΑ������c���Բ�ͬ�S�̵��㷨���F(xi��n)�M�л���������ˣ����a�ı�y���c���؏�ʹ���Եõ��ӏ������㷨�ĺ����c�u������ֱ�ӣ������㷨Ҳ�����ڼ��ɵ�ϵ�y(t��ng)֮�С����wϵ�y(t��ng)�_�l(f��)׃�ø��졢���`��Ķ����Ј��е���K�Ñ��˸����T�������r�Įa(ch��n)Ʒ��
�P(gu��n)�I�~��Bluetooth
Ƕ��ʽϵ�y(t��ng)
DSP
�f(xi��)�h�{����Bluetooth���f(xi��)�h�˜������{���e�dȤС�M��Bluetooth
SIG���l(f��)���ģ�1999��l(f��)����Bluetooth
1.0�棬2001��2�°l(f��)����Bluetooth1.1�档ĿǰSIG�ɆT�ѽ�(j��ng)�l(f��)չ��3000�����ҡ��{���f(xi��)�hҎ(gu��)���ğo��ͨ�Ř˜ʣ���������Ո��2.4GHz��ISM�l�Σ�����GFSK���l���g(sh��)�͕r���p����TDD�����g(sh��)��ͨ�ž��x��10�����ң�Blue
tooth
1.0��˜�Ҏ(gu��)���Ĕ�(sh��)��(j��)��ݔ���ʞ�1Mbps����Ҫ�m���ڸ��N�̾��x�ğo���O(sh��)�以�B���È��ϡ������ṩ�c���c���c�����c�ğo���B�ӡ�1
������|������{���f(xi��)�h����1.1
�{���f(xi��)�h�wϵ�{���f(xi��)�hҎ(gu��)���������ąf(xi��)�h��ģʽ��D1��ʾ���{���wϵ�Y(ji��)��(g��u)�еąf(xi��)�h�ɷ֞��Čӣ����ąf(xi��)�h���������ƅf(xi��)�h��Baseband�����·����f(xi��)�h��LMP����߉�·���Ƒ��Åf(xi��)�h��L2CAP�������հl(f��)�F(xi��n)�f(xi��)�h��SDP����
��|����f(xi��)�h��RFCOMM���Ԓ���Ϳ��ƅf(xi��)�h��TCS���M�ơ�AT��������x�f(xi��)�h��PPP��UDP/TCP/IP��OBEX��WAP��vCard��vCal��IrMC��WAE���څf(xi��)�h�У�Ҏ(gu��)���˞������������LMP��Ӳ����B(t��i)�����ƼĴ����ṩ����ӿڵ����C�������ӿڣ�HCI�����ڲ�ͬ�đ���ģʽ�£�HCI��̎��λ�ò�ͬ��������λ��L2CAP�����棬Ҳ������L2CAP֮�ϡ�1.2
��|����f(xi��)�h����ģʽ����ETSI�˜ʵ�TS07.10�����RFCOMM�f(xi��)�h���ṩ��һ������L2CAP�f(xi��)�h֮�ϵĴ��ڷ��摪��ģʽ���{���f(xi��)�h1.0���У�RFCOMM�ṩ���όӷ���ģʽ��Ҫ�����N����9�RS-232�ӿڷ���ģʽ����Modem����ģʽ�Ͷമ�ڷ���ģʽ�����͵�RFCOMM����ģʽ��D��D2��ʾ��
1.3
�{��Ƕ��ʽ����ģʽ�H�H��RFCOMM�f(xi��)�h����A(ch��)�����鴮�ڵ���|������ã��o�����������{���O(sh��)��đ��÷������������{���O(sh��)��đ��Ãrֵ��ĿǰӋ��C�c�ⲿ�O(sh��)��ĽӿڷN��࣬���^��Ҋ����RS-232��RS-485��Parallel
Port��CAN������SPI������I2C�����ȡ����Ҫʹ�{���O(sh��)���ڸ��N���ϰl(f��)�]���ã����ʹ�{���O(sh��)��߂��m���@Щ���È��ϵĶ�N�ӿڹ��ܡ�ʹ��DSP��(sh��)����̖̎��������Ƕ��ʽ�����������H���F(xi��n)�{�������O(sh��)��ij�ʼ�����{���ߌӅf(xi��)�h������������ӿ��`������c�����Է���،��{����|����f(xi��)�h�M����Ч�Uչ�����w����ģʽ��D3��ʾ��2
ϵ�y(t��ng)Ӳ���Y(ji��)��(g��u)��ϵ�y(t��ng)�Ę�(g��u)����Ӳ���Ϸ֞�ɂ����֣��{�����������l���ֲ��Ð����ţ�ERICSSON����˾�ṩ���{��ģ�KROK101007��Ƕ��ʽ��������������TI��˾��TMS320VC54Xϵ�е�DSP��(sh��)����̖̎������
2.1
ERICSSON�{��ģ�KROK101007�Ǹ���(j��)�{��Ҏ(gu��)��1.0�棨Bluetooth
1.0B
Version�����O(sh��)Ӌ�Ķ̾��x�{��ͨ��ģ�K���������������ϲ��֣���������оƬ��Flash�惦����RadioоƬ����������2.4GHz��2.5GHz��ISM�l�Σ�֧�����͔�(sh��)��(j��)�Ă�ݔ�������Ϲ��܅���(sh��)�У�Bluetooth
1.0B�A�J�C��2��RF���l����ݔ�����ṩFCC��ETSI�m�e̎�������460
KB/s
UART��(sh��)��(j��)��ݔ���ʣ��ṩUART��USB��PCM��I2C�ȶ�NHCI�ӿڣ��ṩ��(n��i)������(n��i)���A��HCI��ܣ��c���c���c�����c������Ƕ��ʽ���α��o��
ROK101007�e�m��Ӌ��C������O(sh��)�䡢�ֳ��O(sh��)�䡢�˿��O(sh��)��ʹ�á����(n��i)�����{���f(xi��)�h��(g��u)�ܼ���(n��i)��ϵ�y(t��ng)��D��D4���D5��ʾ��2.2
DSP̎����TMS320C54X��16-bit���cDSP���m�ϟo��ͨ�ŵȌ��rǶ��ʽ���õ���Ҫ��C54xʹ���˸��M�Ĺ���Y(ji��)��(g��u)��CPU���Ќ���Ӳ�����g(sh��)�\��߉��������Ƭ��(n��i)�惦����������Ƭ��(n��i)���O(sh��)�Լ��߶Ȍ��I(y��)����ָ���ʹ����и߶ȵIJ����`���Ժ��\���ٶȡ���Ҫ���c���£��\���ٶȿ죺ָ�����ڞ�25/20/15/12.5/10ns���\��������40/50/66/80/100MIPS����(y��u)����CPU�Y(ji��)��(g��u)����(n��i)��1��40λ�����g(sh��)�\��߉��Ԫ��2��40λ���ۼ�����2��40λ�ļӷ�����1��17��17��Ӳ���˷�����1��40λ��Ͱ����λ������4�l��(n��i)��������2����ַ�a(ch��n)�����ȡ����M��CPU��(y��u)���Y(ji��)��(g��u)����ʹDSP��Ч�،��F(xi��n)�o��ͨ��ϵ�y(t��ng)�еĸ��N���ܡ�
���ķ�ʽ��54xϵ��DSP������3.3V��2.7V늉��¹���������ЩDSP��(n��i)�˲���1.8V늉������ԜpС���ġ��������O(sh��)�����˘˜ʵĴ��пںͷ֕r���ã�TDM�������⣬54x߀�ṩ�˶�·���_���ڣ�McBSP�����ⲿ̎����ͨ�ŵ�HPI���нӿڡ�2.3
ϵ�y(t��ng)��(g��u)�ɱ�ϵ�y(t��ng)�У����Æ�5V�Դ��늣�Ƕ��ʽϵ�y(t��ng)�������c�{��ģ�K֮�g��HCI�ӿڲ���UART��ʽ��Ӳ����(g��u)�ɿ�D��D6��ʾ������ϵ�y(t��ng)�֞��Ă����֣��l(f��)��C��Ƕ��ʽ���������Դ�������ӿ�߉����1���l(f��)��C���{��ģ�KROK101007���迹��50�����쾀��(g��u)�ɡ���ʼ���A�Σ�ģ�K���տ�����ͨ�^UART�l(f��)�͵�HCI������F(xi��n)�{���O(sh��)��ď�λ�����ӡ���ַ��ԃ�����l�㷨���Ԅӌ����ȳ�ʼ���������c�������{���O(sh��)�佨���ɿ��������·�����������·�M�������ļ��ܡ��ڔ�(sh��)��(j��)�����A�Σ����տ�������HCI�(q��)��ģ�K���́���HCI��(sh��)��(j��)������(j��ng)�^ģ�K��HCI�̼���HCI
Firmwire���D(zhu��n)���������(sh��)��(j��)�����ͽo�����f(xi��)�h�ӣ�Baseband��̎�����������ό��́��Ĕ�(sh��)��(j��)�M�н�a������׃?y��u)���l(f��)�͵�λ��(sh��)��(j��)���������O(sh��)�������l�㷨�����ø�˹�l���I�أ�GFSK�����a��ʽͨ�^�쾀�ͳ�ȥ�����Ք�(sh��)��(j��)�r�����෴���^�̌����յ��Ĕ�(sh��)��(j��)�M�о��a���M�ϳ�HCI��(sh��)��(j��)����ʽ��ͨ�^UART���ͽo�����������w���հl(f��)��(zh��)���^�̿��ԅ���ROK101007��(sh��)��(j��)�������փ��Լ��{���f(xi��)�h���P(gu��n)���֡���2��Ƕ��ʽ��������TI�Ķ��c��(sh��)����̖̎����TMS320C54x��Flash
Memory��SRAM�M�ɣ���Ɍ��{��ģ�K�ij�ʼ������(sh��)��(j��)���͡��f(xi��)�h���F(xi��n)�ȹ��ܡ�
��3���ӿڿ���߉�������ýӿںͿ��ƽӿڡ����ƽӿڞ��������HPI�ӿڣ���Ҫ���F(xi��n)ϵ�y(t��ng)���ھ�������ƺ�Flash�ھ����̔�(sh��)��(j��)���Ϳڡ�HPI���ƽӿ�ͨ�^DSP��HPI���C�ӿڌ��F(xi��n)�����ýӿڰ���RS-232/RS-485���нӿ�߉�����нӿ�߉����IEEE488��������SIͬ������߉���ڲ�ͬ��Ƕ��ʽ�����У��քeͨ�^��ͬ�Ľӿ���ʽ���F(xi��n)��Ƕ��ʽϵ�y(t��ng)�c���O(sh��)��������Ľӿڡ����ýӿ�ͨ�^DSP��Ƭ��(n��i)���O(sh��)��enhanced
peripherals������ͨ��I/O�˿�ģ�M���F(xi��n)����4���Դ������ϵ�y(t��ng)ͨ�^��5V�Դ��늣����Ժ��ε؏����O(sh��)��ӿ��Ы@ȡ�Դ���o������Դ�������Դ����ģ�K����TI�����·���ṩ��·늉�ݔ����+3.3V����늉���+1.8V��������(n��i)�˹���늉���3
ϵ�y(t��ng)ܛ���O(sh��)Ӌϵ�y(t��ng)����TI�ṩ��DSP5000ϵ�Ќ��ü����_�l(f��)����CCS1.2�_�l(f��)��ϵ�y(t��ng)ܛ����(g��u)�ɰ������ö˿�ͨ�ż��f(xi��)�hģ�K��L2CAP�f(xi��)�hģ�K��HCI�ӿ��(q��)��ģ�K��HPIͨ��ģ�K��Flash����ģ�K����Ҫ�΄տɷ֞飺ϵ�y(t��ng)��ʼ����Flash���̡����������·����(sh��)��(j��)���ͺͽ��յȡ�����ܛ��������D7�������{��ģ�K�������о�·���ܹ��ܣ�����ڱ�ϵ�y(t��ng)�O(sh��)Ӌ�Л]�п��]ܛ�����ܹ��ܡ��ڌ��H���O(sh��)Ӌ�͑����^���У�����ҕ�䌍�H���íh(hu��n)����ϵ�y(t��ng)̎���ٶȶ�����ܛ������ģ�K���������lͨ�ű������и߿��ɔ_�Ե����c����Ƕ��ʽ�{������ϵ�y(t��ng)���H���ԑ����ڸ��N�K���O(sh��)����ֳ��O(sh��)���g���е��ٟo����(sh��)��(j��)���Q�����ҿɏV���ؑ����ڸ��N���I(y��)�O(sh��)�䡢܊���b��ęz�y�Ϳ����I(l��ng)��]]>
���ꌦDSP���_�l(f��)��һ���Լ��ĸ��ܣ�һ��֮�ԣ��gӭָ�̡������о����ĵ�һ�������(j��)
�ϰ�İ��ž��_ʼ���|DSP���ǕrDSP�_�l(f��)�ڇ���(n��i)��У�����_ʼ��һ�_DSP�_�l(f��)���ӽ�һ�f
߀��ISA�����ģ��ҏ�206�_ʼ240��2407A�����^�a(ch��n)Ʒ����5402��2812��5471�ڮa(ch��n)Ʒ����
Ҏ(gu��)���ƶ���Փ�C�rҲ�о��^�����ڷ������ތ�6X��8Xϵ�Л]�н��|��
�Ұl(f��)�F(xi��n)�ڇ���(n��i)�oՓ�ڹ�˾���У�S��ط����˼ӿ��_�l(f��)����������һ���a(ch��n)Ʒ�_�l(f��)�֞�Ӳ
����ܛ���ɂ������������֣��ɲ�ͬ������ɡ��@�ھ���һ�����g(sh��)�������A(ch��)�Ĺ�˾��
�ɿ��O(sh��)Ӌ���y(t��ng)һҎ(gu��)���f(xi��)�{(di��o)�����΄ղ�����ɵ���r���ǿ��еģ�Ҳ�Ƿ��ϬF(xi��n)���a(ch��n)Ʒ�_�l(f��)
Ҏ(gu��)�ɵġ������ڸ�У�ˆT�����Ӻܴ��о�������Ч�����r�g�̡ܶ����A(ch��)��S���о�
���r����ۡ���衢���O�ܵķ���x�Ͷ������y����Ҳ���@���^���ģ��������f
ϵ�y(t��ng)Ҏ(gu��)���O(sh��)Ӌ�ˣ��r���S���ϰ��Լ�Ҳ��̫�����������Լ����΄գ����������וrҲ��
�I(y��)�ˡ����S���У��DSP������һ���㷨�ӵ��Լ�����������ڰ�������һ�£������_
��Ч���Ϳ����ˣ����ڿɿ����Ǵ�Ҫ�ģ��a(ch��n)�I(y��)���o��Մ���@�ѽ�(j��ng)�㲻�e���ˡ�
�䌍���X��һ��ϵ�y(t��ng)����ɣ�ϵ�y(t��ng)��Ҏ(gu��)��������Ҫ�ģ���Ҏ(gu��)���r��Ӳ���O(sh��)Ӌ��֪�R���J
�R�ǛQ���Եģ���������֪��ʲô�ǿ��еģ�ʲô�Dz����еģ�����ͬ�r����ܛ���O(sh��)
Ӌ�����r���Ϳ��Ժ����ķ���ϵ�y(t��ng)���ܣ����ʹ��VHDL�M��ϵ�y(t��ng)�О���������ϵ�y(t��ng)����
���֡��� ϵ�y(t��ng)�ӽY(ji��)��(g��u)�O(sh��)Ӌ�@�ӵ�������µ��O(sh��)ӋҎ(gu��)�����̣��ɞ�ϵ�y(t��ng)�O(sh��)Ӌ���ҡ��Ŀ��(j��ng)
������tֻ��Ӳ�����̎���ܛ�����̎����oՓ��51��196��߀��DSP�����@�ӡ�
����քeՄՄ�Ҍ�Ӳ����ܛ���O(sh��)Ӌ�ĸ���
Ӳ���O(sh��)Ӌ��ϵ�y(t��ng)�O(sh��)Ӌ���P(gu��n)�I������(n��i)�͇���a(ch��n)Ʒ�IJ��������Ӳ���O(sh��)Ӌˮƽ�ߵ͛Q���ģ�
�κ�ܛ���O(sh��)Ӌ˼��]�пɿ��������d�w���ǿ��И��w������Մ�����WУ���о����ܶ
����_Ӳ���O(sh��)Ӌ������һ��ȫ�µ��O(sh��)Ӌ�c���f��м�����f���ҡ�ԇ��һ���ׂ�Ƭ�ӵ�
����Ҫ�����w�γ���ĉ�����Ķ࣬�����ǹ���������һ��������Ū���û��_�죬
�˵����Ŷ��]�ˡ��r�Ҹ�һ�ΰ������L����(j��ng)�M�ߣ�߀��֪�в��С��䌍�ڇ��⌍��һ��
�Ĺ�˾Ҳ�DZM������Ӳ���ĸ����O(sh��)Ӌ���a(ch��n)Ʒһ����������ͨ�^ܛ���������@�ǹ�˾�İl(f��)
չ���ԣ������˶�������ϣ���F�����B(y��ng)һ��Ӳ���O(sh��)Ӌ������Ҫ��ܛ���O(sh��)Ӌ���r�g�L���M
�ࡣ���O(sh��)ӋdspӲ���r���_ʼ�O(sh��)Ӌ��Сϵ�y(t��ng)�壬ϵ�y(t��ng)�����ְܷ��O(sh��)Ӌ�{(di��o)ԇ��ע��ְ��·
�ķ�(w��n)���Կ��ܲ��������·��Ҫ����뿹�ɔ_�h(hu��n)��(ji��)���ְ��g�����������Դ���ؾ�Ҫ��
���M����10�����ԃ�(n��i)�����ڲ��м��������x�����ø��x�Դ����ӛ�Դ�����ؾ��ĸ�
�_�h����̖�ɔ_��ϵ�y(t��ng)��Σ����ö࣬�ֳ������˺�ҕ���·�幤���������țQ�l����
���Դ���������ְ��·�������ٸ�����r�O(sh��)Ӌ�����·�����{(di��o)ԇ�r�l(f��)�F(xi��n)�Ć��}һ��Ҫ
�ҵ�ԭ���Q����ʹ���w���������Ҫ��ϣ������һ������ٿ�������ԭ�����e�`��
ÿһ�����ܭh(hu��n)��(ji��)���ʂ��������DSP���x��Ҫ����(j��)ϵ�y(t��ng)���ܶ�����2000��һ�����ܱ��^
ȫ�Ŀ����������\�����������ͣ���Ŀǰ�ֿ�����������е͌ӴεĹ��I(y��)��
��ͨ�Ůa(ch��n)Ʒ����ˣ�281X���e��̫�F�������_�l(f��)���g(sh��)�����졣54XX����һ���f(xi��)̎������
�䌍�߶ˮa(ch��n)Ʒ5471�ͺܺã�������*����BGA���b���a(ch��n)Ʒ���_�l(f��)��һ���y�ȡ�����]�Џ�
���^Ƕ��ʽϵ�y(t��ng)�_�l(f��)�������䌍���ԏ�51�����S��˼���ǹ�ͨ�ģ�51����(j��ng)���]����һ
��̎������51�ǘ�ʹ�ó־ú��ձ顣��Ӳ���O(sh��)Ӌ�r����ľ�����������·�O(sh��)Ӌ�ϣ�
����·�O(sh��)Ӌ���`����Ҫ��DSP�����ߵö࣬�y�ȴ�öࡣ���h��]CPLD��
ܛ���O(sh��)Ӌ�ϣ������c��Ҫ�H������ij�N�㷨�Ϳ��Ʋ��ԣ�����ܛ��ϵ�y(t��ng)��ܵ��ƶ�����
����ϵ�y(t��ng)���x��͌��F(xi��n)���㷨�Ϳ��Ʋ���ֻ�����м����Ժ����ӳ�����ӳ����g����(sh��)
��P(gu��n)ϵ�����h�O(sh��)Ӌܛ���r�ܾ��в���ϵ�y(t��ng)����(sh��)��(j��)�Y(ji��)��(g��u)�;��gԭ�������֪�R���e��
ʹ��C����DSP�ă�(n��i)��Ӳ���Y(ji��)��(g��u)һ��Ҫ���գ��e���Д�Y(ji��)��(g��u)�����̡���ˮ����������Ȼ
�w����֪����ô�w�ġ����Z���x�����Ү��r���@ô�o�Լ�Ҏ(gu��)�����Ⱦ�20�����ҵąR����
��ÿ�����a�����^4K��ʹ���Z�䷶�����wȫ���Z���60����70�����ڴ˻��A(ch��)��ʹ��C��
�F(xi��n)�ڰl(f��)�F(xi��n)��C��(g��u)����������w��ܣ�����ϵ�y(t��ng)�����^����䲻���׳��e�����ҬF(xi��n)��������
ASM����(j��)UCOSII��˼���،��Լ��IJ���ϵ�y(t��ng)������ϵ�y(t��ng)���r��Ӱ푱��^����\���㷨һ��
����MATLAB����C����ASM���k�������{(di��o)ԇ��(y��u)�����@��ă�(y��u)�����Ά������Ã�(y��u)������(y��u)����
���Ǹ���(j��)��(sh��)��(j��)�����c��׃�\�㷽�����Գ�������C��ģ�̖�䌍���w���S�༼�ɣ�������(sh��)
�鳣��(sh��)�r�Ϳ��ԷŴ�(sh��)��λ�����λ���k���M�У����ȸ��ٶȿ졣�@Щ�k��ֻ������
��ASM�Z�Բ���ASM�Z��˼���ŕ��쾚���á�����������VһЩ���㷨�e�ǿ����㷨��
���ѣ�ǧ�f��Ҫ�S���u��һ���㷨�ă�(y��u)�ӣ��ڳ����г���ʹ��a��(y��u)���ij̶�����Ӱ���
����Ч���Éģ��������㷨������˼�롣�䌍�ڌ��H������PID����PI��PD�͉��ˣ���(j��ng)
Ԫ��ģ����С���m�����о��͌�Փ�ģ�ģ���ڌ��H���õĶ�һ�c����Ҫ��С�ձ��õı�
�^���죬���ٺ��ձ��ˣ��@�cҲ���⣬С�ձ����ǻ����S�������F(xi��n)��㲻�������@��
��߀���ã��}��Ԓ��
��������f���ǣ����҂��挦�Ј�Ҫ��r���a(ch��n)Ʒ�������]���ǿɿ��ԡ����ܡ��r�����
�����õ�ʲôоƬ���ڝM�����ܵĻ��A(ch��)�ϽY(ji��)��(g��u)Խ���ξ�Խ�ɿ���оƬԽͨ�Ãr���Խ��
������51�Ͳ���196������2407�Ͳ���2812�����ǰ�оƬ�������I�c���ø߳ɱ��Aȡ����
�����oՓ2000߀��5000��6000ϵ�ж����Ј�ǰ�����P(gu��n)�I��Ҫ������
�@ȡ֪�R�ķ�����̎���Ŀ����������ͨ�ģ����w���f���Dz�Ҫ��Ŀ�ⶢ����Ӳ��߀��
��ܛ���ϣ���ASM߀��C��Ҫ�ڄ��ִ�û��A(ch��)������Լ���ϵ�y(t��ng)���w�O(sh��)Ӌ����������ϵ�y(t��ng)
���۹⿴���}����ʲô������DSP���еĮ��I(y��)��3000���е�5000��8000�������\����P(gu��n)ϵ
�⣬��Ҫ�����㌦������J�R��Ⱥ߶ȡ���һֱ��ӛס�@��Ԓ����ǰ;������ʲô��
��ǰ;���]ǰ;������ʲô���]ǰ;��
��. �c���f���@�����棬���I(y��)�O(sh��)Ӌ�Ǹ�240�����ώ��ĉ���������һ�c�|�����@���g��Ҫ
�nj�DSP�ĸ��N���A(ch��)֪�R����Ϥ�c���⣬��DSP�������������ڹ�˾�����Ժ����M��
˾���������һ���Ŀ��Ҫ��5410Ҫ�ҽ��֡��f��Ԓ���ڌWУ���g��5000�ĕ����]�п�
�^һ�ۣ��ɛ]�k����ֻ�ܿ��Լ��ˡ����^�õ�����2000DSP�Ļ��A(ch��)�ܺá����^�Ŀ����
��һ�����ھ�ȫ��������5000��ָ�DSP�ĽY(ji��)��(g��u)���]��ô��������ĿӲ���ѳ��ͣ���
Ҫ���㷨���@�ӣ�����һ��������Ϥָ���c�Ŀ���P(gu��n)�ij��ڶ�������Ҳ���_ʼ����
�ˡ��낀���Ժ��Ҍ�5410Ҳ���ú����˵ģ���Ȼ��Ҫ߀���v���㷨���档�@���Ŀ̫��
�����Ă��°ɣ�ϵ�y(t��ng)�������Ҿ����ģ���Ҫ����64λ�Ӝp�˳��˷��_�������r�����
һЩ�㷨���F(xi��n)������һ������ϵ�y(t��ng)����2407�_�l(f��)�ģ�Ӳ����Ҫ��ֱ��׃�l������2407��
�������O(sh��)�YԴȫ���õ��ˡ��F(xi��n)���ҿ����@���Կ�һ��ɣ�TI��2000ϵ���c5000ϵ�е���
����Ϥ��Ҫ��ȥ�Դ�����ϵ�y(t��ng)���]���}�������ǰ��Ҹ�DSP�Ľ�(j��ng)�v�����f��һ�µİɣ���
�@�����댦���ڌW����WDSP���y�ւ��fһ����ǣ�DSP�����Ǻ��y����Ȼ���@��ǰ����
��Ļ��A(ch��)Ҫ�ã��҆�Ƭ�C���ӿڶ�߀�У��������ǏĆ�Ƭ�C�ij�DSP�ġ����ˆ�Ƭ�C�Ļ�
�A(ch��)��ȥ�W2000���е�DSP�������DSP��ָ2000ϵ�У������f����ֹ������Ϳ���DSP��
��һ��super microcontroller�ˡ����֮�£�DSP���˱Ȇ�Ƭ�C���˸��S�����O(sh��)�ӿڣ�
SPI,SCI��CAN��PWM��CAP��QEP�ȵȣ���������һ�K��Ƭ�C��ֻ���^�چ�Ƭ�C���f��Ҫ��
��оƬ�Ĺ�����DSPȫ����������һ�KоƬȥ�ˣ��ҬF(xi��n)�ڿ�DSPҲ����@ô���Ρ�ǰ����
���ᵽDSP��Ҫ�����㷨���@��Ԓ��һ����Ƭ���ԣ� TI�кܶ�ϵ�е�DSP���F(xi��n)��������D
SP��Ҫ��2000ϵ�С�3000ϵ�С�4000ϵ�С�5000ϵ�С�6000ϵ�С�����2000�c5000ϵ��
�Ƕ��cDSP�⣬����ľ��鸡�cϵ�С� TI��2000ϵ����Ҫ�L̎�������ڿ���ϵ�y(t��ng)�����
�����YԴ�dz��S����ǰ���ᵽ���ڿ���ϵ�y(t��ng)���õ���һЩ���O(sh��)2000ϵ�о���Ƭ��(n��i)������
�� TI��5000ϵ����Ҫ�L̎�����ڔ�(sh��)����̖���㷨̎�����@�����v�㷨̎����Ҫ��ָ�ڔ�(sh��)
����̖̎��r��һЩ�㷨����FIR��IIR��FFT�ȵȡ�5000ϵ�е�DSP���ٶȱ�2000�죬24
07���ֻ�ܵ�40M��2800ϵ�г��⣬5410��DSP�����_��160M����F(xi��n)���҂���Ҫ�Á�����(sh��)
����̖�����̎���Լ����ε��o�B(t��i)�D��̎�����@��һЩ���YԴ��Ҫ̎���еȵ�һЩ�㷨
�� TI��6000ϵ����Ҫ�����ڌ��r�D��̎�����@�����t�����㷨̎����һ���Ӳ������
���ƣ��҂�����TI��DSK���ټ�����������Y(ji��)�ϡ�
��. ʹ��C/C++�Z�Ծ�������DSP�����ע����� 1�� ��Ӱ푈�(zh��)���ٶȵ���r�£�����ʹ
��c��c/c++�Z���ṩ�ĺ���(sh��)�죬Ҳ�����Լ��O(sh��)Ӌ����(sh��)���@�Ӹ�����ʹ�á��ÿp������(y��u)��
̎�������磺�M�н^��ֵ�\�㣬�����{(di��o)��fabs()��abs()����(sh��)��Ҳ����ʹ��if...else..
.�Д��Z�������� 2�� Ҫ�dz�֔����ʹ�þֲ�׃��������(j��)�Լ��Ŀ�_�l(f��)����Ҫ�����M
���ܶ��ʹ��ȫ��׃�����o�B(t��i)׃���� 3�� һ��Ҫ�dz���ҕ�Д��������Ć��}���ܶ�����
���Д����������{(di��o)�÷�ʽ��������䌍�Д��������е��Д���������ȡ���ģ�dsp�Dz��J
���ֵģ���ֻ�J��ַ�����Д�������Ҫ���¶�λ���@һ�c����Ҫ�� 4�� Ҫ���_dspܛ��
�_�l(f��)�ĵ�һ���nj����ô惦���g�ķ������惦���g����É��P(gu��n)ϵ��һ��dsp����T��ˮƽ
������dsp���҂��ЃɷN���Q�Ĵ惦���g��һ�N���������g����һ�N��ӳ����g��������
�g��dsp�Ͽ��Դ�Ŕ�(sh��)��(j��)�ͳ���Č��H���g�������ⲿ�惦�������҂��Ĕ�(sh��)��(j��)�ͳ�����K
�ŵ��������g�ϣ����҂�������ֱ���L���������҂�Ҫ�L���������g����횽�����ӳ��
���g���У�������ӳ����g�����ǂ���̓�����g���ǂ������ڵĿ��g�����ԣ�������ӳ
����g�h�h���ڌ��H���������g����Щӳ����g����ioӳ����g��������߀������һ�N
�ӿڡ�ֻ����Щ�������gӳ�䵽��ӳ����g�����҂��������L�����x��?q��)����Ĵ惦���g
�� 5�� �M���ܵp�ٳ����\�㣬���M���ܶ��ʹ�ó˷��ͼӷ��\����档 6�� ���ti
��˾�������ܛ���������ṩ��dsplib�������ĺϷ��ӳ���칩�{(di��o)�ã����M���ܵ��{(di��o)��
ʹ�á��@Щ�ӳ����ʹ���ÅR�����ɣ�������Ҫ֮̎��ͨ�^��tms320�㷨�˜ʜyԇ����
�ң����õĔ�(sh��)����̖̎���㷨���а������� 7�� �M���ܵز��Ã�(n��i)(li��n)����(sh��)����������һ��
�ĺ���(sh��)����������ߴ��a�ļ��ɶȡ� 8�� �����L�����������M������c�Z�Զ�����
c++�Z�ԡ��҂��˸е��mȻc++�K���a�L��һЩ������(zh��)���ٶț]��Ӱ푡� 9�� �����
c5000��double�ͺ�float�;�ռ��2���֣����Զ�����ʹ�ã����ң�����ֱ�ӌ�int���x
�ofloat�ͻ�double�ͣ������M���ܵض�ʹ��int��(sh��)��(j��)��ʹ��棡�@һ�c��Ҫע�⣡�� 1
0�� �����������Ҫ����һ�����У����g�����@�����О�Y(ji��)β��ʾ���� 11�� ��đʹ��
λ�\������dz����ã��� 12�� 2003��6�·ݏ�ti�ľW(w��ng)վ���µ����P(gu��n)��tms320c67xϵ��d
sp�Ŀ����㷨�죬���ǣ�tms320c5000��c6000ȫϵ�еĿ����㷨�춼�����ˣ��@Щ�㷨
����ɹ�c/c++�Z��ֱ���{(di��o)�ã���(y��u)���̶�100%�����H���̕r�M���ܵ�ʹ�ã����d�r����ͬ
�r���d���f���ęn��asciiԴ�����Ը���(j��)�Լ���Ҫ�����ģ���ǰ���������ݣ�
1 DSP�İl(f��)չ�v��
�ڔ�(sh��)����̖̎�����g(sh��)�l(f��)չ�ij��ڣ������o50��60��������˂�ֻ����̎��������ɔ�(sh��)����̖��̎����һ���J�飬�����ϵ�һ����ƬDSPоƬ��1978��AMI��˾�l(f��)����S2811��1980�꣬�ձ�NEC��˾�Ƴ���D7720�ǵ�һ������Ӳ���˷���������DSPоƬ���Ķ����J���ǵ�һ�K��ƬDSP������
�S����Ҏ(gu��)ģ�����·���g(sh��)�İl(f��)չ��1982���������݃x����˾�������ϵ�һ��DSPоƬTMS32010����ϵ�Юa(ch��n)Ʒ����־�����r��(sh��)����̖̎���I(l��ng)����ش�ͻ�ơ�TI��˾�S���Ƴ��˵ڶ���DSPоƬTMS32020����ϵ�У�����TI��˾�ѽ�(j��ng)�Ƴ����������DSPоƬTMS320C62X/C67X��TMS320C64X��оƬ��
����Analog Device��˾��DSPоƬ�Ј�Ҳ��һ���ķ��~���Ƴ���һϵ�о����Լ���ɫ��DSPоƬ�����䶨�c��DSPоƬADSP2101/2103/2105��ADSP2111/2115��ADSP2161/62/64�����cDSP��ADSP21000/020��ADSP21060/21062�ȡ�
20���o80����ԁ���DSPоƬ�õ���ͻ�w���M�İl(f��)չ�����\���ٶȁ�����MAC��һ�γ˼��\�㣩�r�g�ѽ�(j��ng)��80������ڵ�400 ns������10 ns���£���TI��˾��TMS32054X��TMS320C62X/67X�ȣ���̎����������ˎ�ʮ����DSPоƬ�����_��(sh��)����1980���64�����ӵ��F(xi��n)�ڵ�200�����ϣ����_��(sh��)��������Ҳ�ӏ��˽Y(ji��)��(g��u)���`����[1>��
2 DSPϵ�y(t��ng)��оƬ�Ļ����Y(ji��)��(g��u)
2.1 DSPϵ�y(t��ng)�Ļ����Y(ji��)��(g��u)
ϵ�y(t��ng)����Ҫ̎������̖һ�����Ȼ�l���µ�ģ�M��̖���@����Ҫ���Ȍ�ݔ�����̖�D(zhu��n)�Q�锵(sh��)�ֵ����̖���@����ҪA/D��ģ��(sh��)�D(zhu��n)�Q��ģ�K��A/Dģ�K��ģ�M��̖�D(zhu��n)�Q�锵(sh��)�ֵı�������ݔ��oDSPϵ�y(t��ng)��DSPϵ�y(t��ng)����(sh��)����̖�M��ij�N̎��֮��һ��߀��Ҫݔ����ģ�M��̖�����˂�ʹ�ã��������õ���D/A����(sh��)ģ�D(zhu��n)�Q��ģ�K����̎����Ĕ�(sh��)����̖�D(zhu��n)�Q��ģ�Mֵ������ϵ�y(t��ng)�Ę�(g��u)����D1��ʾ��

��(sh��)����̖̎���Y(ji��)��(g��u)��(w��n)���Ժã����؏��Ժã����Դ�Ҏ(gu��)ģ���ɣ�ʹ����̖̎�����ܸ����s���ֶθ��`����ȸ��ߡ�
2.2 DSPоƬ�ĽY(ji��)��(g��u)���c[2>
DSP̎��оƬ�������m����̖̎���\�����Ҫ���Y(ji��)��(g��u)�cͨ�õ�����Ӌ��C�����̎������ȣ����^��IJ�ͬ����Ҫ�Ď��c�飺
(1)���Ќ��õ����g(sh��)��Ԫ����Ӳ���˷�����DSP��(n��i)���O(sh��)��Ӳ���˷�������ɳ˷�����������߳˷��ٶȡ�
(2)��������Ŀ����Y(ji��)��(g��u)��������Y(ji��)��(g��u)���@�N�Y(ji��)��(g��u)ʹDSP���Ъ����ĵ�ַ�����͔�(sh��)��(j��)����������ͬ�rȡ��ַ�Ͳ�����(sh��)��
(3)��ˮ̎������ˮ���g(sh��)ʹ������ͬ�IJ�������ͬ�r��(zh��)�У�̎������(n��i)��ÿ�lָ��Ĉ�(zh��)�з֞�ȡַ����a����(zh��)�е��A�Σ���ͬ���A�β��Ј�(zh��)�У�����˳����(zh��)�е�Ч�ʺ��ٶȡ�
(4)���ٵ�Ƭ��(n��i)�惦����DSPоƬһ���(n��i)�������г���͔�(sh��)��(j��)�惦�����L���ٶȿ죬���⿂���ӿڵĉ�������߳����(zh��)�е��ٶȡ�
һЩ��������ܵ�DSPоƬ߀����һЩ���õ��O(sh��)Ӌ�Y(ji��)��(g��u)���@�ﲻһһ�г�����֮��DSP�����ϵ����c�ܴ�̶�����ᘌ���(sh��)����̖̎���㷨�����c��ᘌ��ԵؽM�Ɍ��õĽY(ji��)��(g��u)���ԝM��̎������Ҫ��
3 DSPоƬ�Įa(ch��n)Ʒ���Ј�
3.1 �����I(l��ng)����Ј�
�ڽ�20����ĕr�g�DSPоƬ�đ����ѽ�(j��ng)��܊�¡����պ����I(l��ng)��U����̖̎����ͨ�š����_�����M���S���I(l��ng)����Ҫ�����У���̖̎����ͨ�š��Z�����D��܊�¡��x���x�����Ԅӿ��ơ��t(y��)������������ȡ�
DSP��Ҫ�����Ј���3C��communication��computer��consumer����ͨ�š�Ӌ��C�����M��I(l��ng)����ռ�Ј��������^90%�����ҿ��w�Ј�Ҏ(gu��)ģ�ڲ����U���ڔ�(sh��)�ֻ������˻��;W(w��ng)�j�����Ƅ��£��AӋδ����������L�ʸ��_40%����ȫ���DSP�Ј��У�TI��˾��ռ���^��ռ�����Ј���45%���~���������Ӎ(28%)��ADI(12%)��Ħ���_��(12%)��������˾(3%) [3> ��
3.2 ������Ҫ��DSPоƬ���칫˾����a(ch��n)Ʒ
��1��TI��˾��
TI��Texas Instruments����˾�ژI(y��)��һֱ̎���I(l��ng)�ȵĵ�λ�����꣬TI��ԭ����TMS320C1X��TMS320C25��TMS320C3X/4X��TMS320C5X��TMS320C8X�Ļ��A(ch��)�����Ƴ���3�N���ԃr�ȵ�DSPϵ�У�TMS320C2000��TMS320C5000��TMS320C6000ϵ�С��@3�NоƬ�����҇�����̖̎��Ӳ���I(l��ng)����Ҳ�Ƿdz��V����������Щ��Ҫ��B��
TMS320C2000ϵ����Ҫ���ڹ��I(y��)�����I(l��ng)���ṩ��ȫϵ�еĸ����ܿ���оƬ�����a�\��Ч�ʸߡ������^���Ŀ��ƹ���֮�⣬߀�ṩ�˷���Ľӿ��c����������������B����Ҫ��̖��TMS320C24X��28Xϵ�С�
TMS320C5000ϵ�О�����ܵĵ��Ķ��cDSPоƬ��̎���ٶ���߿����_��900 MIPS�����ĺܵͣ������_��0.33 mA/MHz���dz��m���ƄӺ��ֳ�ϵ�y(t��ng)�đ��á���Ҫ��TMS320C54X��55Xϵ�С�
TMS320C6000ϵ�О���һ�����ԃr��DSPоƬ���Ǹ߶�DSP̎�����Ĵ�����C6000ϵ�е�DSP���c�\������_��1200��8 000 MIPS�����f�lָ��/�룩�����c�\������_��600�� 1 800 MFLOPS�����f�θ��c����/�룩���\���ٶȡ���Ҫ�ж��cϵ�е�TMS320C62X���cϵ�е�TMS320C67X��TMS320C64X��TI�����Ƴ��ĸ����ܶ��cDSP̎�������r��ٶ���ߵ�1 GHz����Ƭ̎���������_��8 000 MIPS��
��2��Analog Device��˾��
ADI��˾��DSPĿǰ��Ҫ�֞�3��ϵ�У�SHARC��Blackfin��TigerSHARC��
SHARCϵ��һֱ�����_���{��̖̎�����I(l��ng)�����кܸߵ��u���ܶ����á�܊�õ���̖̎��C�ж����Կ���SHARC����Ӱ����Ƭ̎����������SHARC֮�����܉���ͨ����̖̎���I(l��ng)�����@ô�ߵ��u����ȫ������ADI��(y��u)���Ƭ�g���B���g(sh��)��LINK�ڣ��������@��LINK�ڿ��Ժܷ���،���Ƭ����ʮƬSHARC�B�������M��DSP��У��Ķ��چ�Ƭ̎�������_����Ҫ��Ĉ�������DSP��оͺ������_���ˡ�
Blackfin�ǽ������Ƴ���ᘌ�����Ҫ����^�ߣ�ͬ�r����Ҫ���ֱ��^�͵Ĉ����������߂�ă�(y��u)�c���m���ڱ�yʽͨ�Ůa(ch��n)Ʒ�Б��á�
TigerSHARC�Ǐ�SHARC���M�ĸ߶�DSP�����ij��F(xi��n)��ADI��˾��DSP�ڸ߶��I(l��ng)�����_��(chu��ng)�˚vʷ�Եľ��档���Ƴ��ĵڶ���TigerSHARC ADSP-TS201S���l���_600 MHz��̎���������_14.4 GOPS��߀�г���������RAM��ʹ��һ�������ڸ߶��I(l��ng)��Ó�f�����������m��ܛ���o��늵đ��á�
DSP�ѽ�(j��ng)�l(f��)չ�ɞ���һ�N����ļ��g(sh��)��Ҳ��һ�N����Įa(ch��n)Ʒ�����ڔ�(sh��)����Ϣ�r��ռ��(j��)Խ��Խ��Ҫ��λ�ã��������Ј��ĔUչ߀��������Ŀ��g��DSP�����ܡ��r������ǛQ�����Ј���������Ҫ���ء�����(zh��n)���ߵ����ܣ��M���ܽ��̓r����ģ�һֱ��DSP���Ŀ�ˡ�
4 DSP̎��ϵ�y(t��ng)�İl(f��)չ�F(xi��n)��
4.1 ���H�l(f��)չ�F(xi��n)��
���ԇ��HDSP̎���l(f��)չ�ĬF(xi��n)�������̘I(y��)����̖̎���O(sh��)��һֱ���������ٵİl(f��)չ���^���W���ȿƼ�������������H�I(l��ng)�ȵĵ�λ����������DSP research��˾��Pentek��˾��Motorola��˾�����ô�Dy4��˾�ȣ������ܶ��ѽ�(j��ng)�l(f��)չ���ஔ���Ҏ(gu��)ģ������Ҳ���l(f��)���ҡ��҂��ć��H֪��DSP���g(sh��)��˾�l(f��)���Įa(ch��n)Ʒ�оͿ����˽�һЩ�����������M�Ĕ�(sh��)����̖̎��ϵ�y(t��ng)����r��
��Pentek��˾һ��̎����4293������ʹ��8ƬTI��˾ 300 MHz��TMS320C6203оƬ������19 200 MIPS��̎��������ͬ�r������8Ƭ32 MB��SDRAM����(sh��)��(j��)����600 MB/s��ԓ��˾��һ��̎����4294������4ƬMotorola MPC7410 G4 PowerPC̎�����������l��400/500 MHz���ɼ�����256K��64 bit����߾���16MB��SDRAM��
ADI��˾��TigerSHARCоƬҲ�������ɫ�ąf(xi��)ͬ�������������ԽM�ɏ����̎������У����T���I(l��ng)���e��܊���I(l��ng)�@���ˏV���đ��á���Ӣ��Transtech DSP��˾��TP-P36N����������4��8ƬTS101b��TigerSharc��оƬ��(g��u)�ɣ��r� 250 MHz������6��12 GFLOPS��̎��������
DSP���îa(ch��n)Ʒ�@�óɹ���һ����־�����M��a(ch��n)�I(y��)������������20���У��@һ�M���ڲ����؏��M�У����������ڲ���sС���ڔ�(sh��)����Ϣ�r����������¼��g(sh��)���®a(ch��n)Ʒ��Ҫ���ٵ������Ј�����ˣ�DSP�Įa(ch��n)�I(y��)���M��߀����Ҫ�����M�С��S�������ļӄ���DSP���a(ch��n)���S�r�{(di��o)���l(f��)չҎ(gu��)������ȫ����Ј�Ҏ(gu��)�������ƵĽ�Q�����������µ��_�l(f��)�v�꣬������a(ch��n)�I(y��)���M�̡�
4.2 �҇��l(f��)չ�F(xi��n)��
�S���҇���Ϣ�a(ch��n)�I(y��)�İl(f��)չ��������҇��Ĕ�(sh��)����̖̎��W�ưl(f��)չ�^�졣DSP̎�����ѽ�(j��ng)���҇��Ĕ�(sh��)��ͨ�š���̖̎�������_����ӌ������D��̎���ȷ���õ��ˏV���đ��ã���ƌW���g(sh��)�͇���(j��ng)�����O(sh��)��(chu��ng)���˺ܴ�rֵ��ȫ���кܶ��У�����ЙC��(g��u)����̖̎�팍��Ҷ��ڴ����о����ܸ��ߵĔ�(sh��)����̖̎���O(sh��)�䣬ȡ���˺ܶ��о��ɹ����҇��Ŀ����ˆTͨ�^�����M��DSPоƬ���о����ѽ�(j��ng)���Ƴ�һЩ������̎���O(sh��)��Ľ�Q�����������ڰ弉PCB�O(sh��)Ӌ���棬Ҳȡ���ˌ��F���O(sh��)Ӌ��(j��ng)
���҇�ij��Ӽ��g(sh��)�о������Ƶ�DSP���_��(sh��)����̖̎��ͨ��ģ�K��������ʹ����6ƬADSP21060�ʹ�Ҏ(gu��)ģ�ɾ���������(g��u)��ͨ��̎��ģ�K��ͨ�^��̖̎���㷨�����O(sh��)Ӌ��ϵ�y(t��ng)����(sh��)��(j��)���O(sh��)Ӌ��̎���΄շ����{(di��o)�ȳ����O(sh��)Ӌ�����F(xi��n)���ٌ��r���_��(sh��)����̖̎�� [4> ����FFT�㷨���������΄շ֞�3����ˮ̎���^�̣�FFT���͔�(sh��)�˷���IFFT�����F(xi��n)��ƬDSP�M�ɲ���̎������33 MHz�r��£�1 024�c̎��ͨ�^�r�g��0.7 ms�����Ԍ��F(xi��n)��ͨ����(sh��)��(j��)�ʞ�1 MHz���pͨ�����й�����2 MHz��
����(n��i)��ij��W�����ƵĻ���TMS320C6201�ĸ��ٌ��r��(sh��)����̖̎��ƽ�_�����F(xi��n)��-2�ď͔�(sh��)FFT�����Sݔ�딵(sh��)��(j��)�ĄӑB(t��i)����16-bit�����Ԍ��F(xi��n)59 ��s��(n��i)���512�c��FFT��130 ��s��(n��i)�������1 024�c��FFT��
���ǣ���ԓ�������҇�����̖̎����Փ�����ٸ�����̎�����O(sh��)Ӌ�����췽���c���H���Mˮƽ߀���^���ࡣ���ң���Ҫ�ĺ���̎������������ȫ��ه�M�ڣ��@Ҳ���҇��댧�w�о��I(l��ng)����Ҫ�����ӏ��Ĺ���֮һ�����s�Ĵ���̎��CPCB�弉�O(sh��)Ӌ������Ҳ����һ�����y��Ҳ����Ҫ�҇������ˆT�l(f��)�P����ƴ���ľ����^�m(x��)�Ŀ̿�Ŭ����
5 DSP���g(sh��)չ��
5.1 ��������DSP����l(f��)չ
Ŀǰ��DSP����(sh��)����RISC������ָ����Y(ji��)��(g��u)���@�N�Y(ji��)��(g��u)�ă�(y��u)�c�dzߴ�С�����ĵ͡����ܸߡ��F(xi��n)�ڸ�DSP�S���������¹�ˇ�����ׂ�DSP�ˡ�MPU�ˡ�����̎���Ԫ������·��Ԫ�ʹ惦��Ԫ������һ��оƬ�ϣ��ɞ�DSPϵ�y(t��ng)�������·��
5.2 ��(n��i)�˽Y(ji��)��(g��u)�Mһ������
��ͨ���Y(ji��)��(g��u)�͆�ָ����ؔ�(sh��)��(j��)��SIMD�������Lָ���ֽY(ji��)��(g��u)��VLIM�����������Y(ji��)��(g��u)������ˮ�Y(ji��)��(g��u)����̎�����ྀ�̼��ɲ��ДUչ�ij�������Y(ji��)��(g��u)�ڸ�����̎������ռ��(j��)������λ��
5.3 �Mһ�������ĺ͎γߴ�
DSP�đ��÷����ѽ�(j��ng)�U���˂���������ĸ����I(l��ng)���e�DZ�yʽ�ֳ֮a(ch��n)Ʒ���ڵ��ĺͳߴ��Ҫ��ܸߣ�����DSP�д����Mһ�������ġ��S��CMOS�İl(f��)չ�����DSP���\���ٶȺͽ����ijߴ�����ȫ���ܵġ�
5.4 �c�ɾ��������Y(ji��)��
DSP���S���µ��I(l��ng)��đ���Ҫ��������PLD��FPGA��M���������L��̎��Ҫ���c��Ҏ(gu��)DSP������ȣ�F(xi��n)PGA������ς��y(t��ng)DSP��������̎��������ŵ�����M��o��ͨ�š���ý�w���I(l��ng)��Ķ�ܺ����ܵ���Ҫ��
1 TI DSP Library����
1��1 TI DSP Library�����c
DSP Lib�ĺ��Č��H����һϵ�н�(j��ng)�^�ֹ���(y��u)���ąR��������a���@Щ���a���b�ں�Y���飮lib���ļ��У���������ɸ��N�\�㡣���������Dz���Ҋ�ġ��@Щ����(�캯��(sh��)��routines)�ɱ�C�����{(di��o)�á����ڽ�(j��ng)�^���ֹ���(y��u)����������Ч�ʶ��dz��ߡ����ڲ�ͬϵ��DSPоƬ��ָ���ͬ����ˣ���ͬϵ��DSPоƬ��DSP LibҲ�Dz�ͬ�ģ���TMS320C5000��DSP LIb�Ͳ�������TMS320C6000�����ǣ�����ϵ��DSP Lib�Ļ����M������ͬ�ģ�һ��������DSP Libͨ����Lib�ļ��A��include�ļ��A�������o���ļ��M�ɡ�����l(w��i)ib�ļ��A���ڴ��*��lib�ļ������(n��i)�����b���ֹ���(y��u)���ąR��������a����һ��DSP Lib�ĺ��IJ��֡��е�DSP Lib߀��*��src�ļ����@Щ*��src�ļ���Ҫ����C�Z�ԺͅR���Z�Ծ����ij���Դ���a��ʹ�Úw�n���ɏ�����ȡ���@ЩԴ���a����include�ļ��A���ڴ�Ÿ����캯��(sh��)���^�ļ���ͨ���@Щ�ļ��֞�C�����^�ļ��ͅR�������^�ļ��ɲ��֡�
1��2 TI DSP Library�����d�Ͱ��b
����DSP Lib�N��࣬�Ҍٿ��xģ�K��ͨ����DSP�_�l(f��)�h(hu��n)��(CCS��Code Composer Studio)���]�����DSP Lib����ˣ�ʹ��һ��DSP Lib֮ǰ������M��DSP Lib�����d�Ͱ��b��
���^���d��������TI��˾�W(w��ng)վW(w��ng)WW��ti��com�����M���d���NDSP Lib�������^���b��������DSP Lib���d�ꮅ���p�����b�ļ����Ԍ������b��Ӌ��C���x����λ��(Ĭ�Jλ�Þ�C����ti)�����b֮�����ڳ����_�l(f��)��ʹ��DSP Lib�Ď캯��(sh��)��
1��3 TI DSP Library��ʹ��
��̎�픵(sh��)��(j��)��͵IJ�ͬ��TI DSP�֞鶨�c(fixed-point)DSP���c(floating-point)DSP�����ڸ��cDSP���ж��cָ������и��cָ�����ˣ������xȡ���cDSPϵ��TMS320C67x��DSP Lib�������xȡ��TMS320C67x DSP Library��TMS320C67x FastRTS Library�ɂ�DSP Lib��ǰ����Ҫᘌ���(sh��)����̖̎���ij��ò��������߄tᘌ�һ�㔵(sh��)�W�\���ͨ�ò�����
2 TMS320C67x DSP Library��
��DSP�M�Д�(sh��)��(j��)̎��r�����e��FFT��FIR�V���Ȳ����l�����F(xi��n)�����ڳ����_�l(f��)�У�ʹ��DSP Lib������@Щ���������������������Ч�ʲ��������̡�TMS320C67x DSP Library�����@�ӵ�һ��DSP Lib������lib�ļ��A��(n��i)�����ļ�dsp67x.lib��Դ�ļ�dsp67x.sr��dsp67x_C.sr-c��dsp67x_sa��src��TMS320C67x DSP Library��Ҫ����TMS320C67xϵ��DSPоƬ�ij����_�l(f��)��ʹ���������FFT�\�㡣
2��1 TMS320C67x DSP Library��ʹ��
ʹ��TMS320C67x DSP Library�ĵ�һ���nj�������ļ���dsp67x��lib�����뵽��ǰ�����У����P(gu��n)���g朽Ӆ���(sh��)�顰-ldsp67x��lib�������������惦�^�ļ���includeĿ�����·�����ӵ���������·���У������P(gu��n)���g朽Ӆ���(sh��)�顰-i pathname�������w�����Ʌ���TI��˾�����P(gu��n)�īI���xȡԓDSP Lib�еĎ캯��(sh��)��DSPF_sp_cfftr2_dit()�������FFT�\�㣬��ʹ�õ��ǻ�2�ĕr�g��ȡ�㷨�����w��ʽ���£�

ͬ�r��ԓ�캯��(sh��)߀��һ���������^�ļ���dspf_sp_cfftr2_dit��h����ʹ�Õr�Ɍ���������{(di��o)��ԓ�캯��(sh��)�ij����С��˕r��ԓ�캯��(sh��)�Ϳ�����һ���ӳ���һ�ӱ����������{(di��o)�ã����wʹ�ô��a���£�

���˱��ڱ��^����ʹ�Úw�n��ָ�ar6x����ԓDSP Lib��Դ�ļ���dsp67x_c.src������ȡ���캯��(sh��)��Դ���a���Եõ��ļ���sp_cfftr2_ dit��c�������Кw�n��ָ��������ļ����惦��CCS�İ��bĿ��£��@���ar6x����ʹ�ø�ʽ�飺
ar6x-x dsp67x_c��src sp_cfftr2_dit��c
�ġ�sp_cfftr2_dit��c���пɵõ��캯��(sh��)��DSPF_sp_cfftr2_dit()����C�Z��Դ���a��������C����顰void sp_cfftr2_dit(float*x��float*w��short n)����ԓ���������һ���ӳ���һ�ӱ��������{(di��o)�á�Դ����(sh��)�͎캯��(sh��)����ʽ��ȫ��ͬ�����H�ϣ��캯��(sh��)���nj�Դ����(sh��)�ij�����a�M���ֹ���(y��u)���ĽY(ji��)����
2��2 ���ܷ���
�քeʹ�Î캯��(sh��)��Դ����(sh��)�����FFT�\�㡣������CCS�Ԏ����������ߡ�Profiler���������ɂ�����(sh��)���ھ��̷�ʽ�IJ�ͬ���������\�Еr�g�ϵIJ����׃ݔ�딵(sh��)�M���L�ȣ��ɵõ����1���е�һ�M��(sh��)��(j��)���ɱ�1���Կ������캯��(sh��)��Ч���h�h����Դ����(sh��)����Ч�ʵ�������S��ݔ�딵(sh��)��(j��)�L�ȵ�׃����׃������ߵ�Ч�ʿ����40��(40��98-1=39��98)���������25�����ң�����ԓDSP Lib�������캯��(sh��)Ҳ������Ĝyԇ�Y(ji��)�����mȻ��ԓDSP Lib�Ď캯��(sh��)����Ч�ʿ������һ����(sh��)���������ڕr�g�����^������ϵ�y(t��ng)���e�nj��rϵ�y(t��ng)���@��Ȼ�Ƿdz����õġ�
�캯��(sh��)��Դ����(sh��)��ȣ���Ч�����˺ܴ���ߣ����@�N������д��r�ġ�����Ҫ���F(xi��n)��ͨ���Խ��͡���ԭ���Ǟ�������ȵ����Ч�ʣ��ڌ����a�M���ֹ���(y��u)�����^���У�������һЩ�����O(sh��)��ͬ�r��ʹ���˴����IJ����ϲ�������̎���Ⱥ����ֶΣ��@��Ȼ���캯��(sh��)��ͨ���Խ��͡����磬�캯��(sh��)��DSPF_sp_cfftr2_dit()��ʹ�Õr�͕��ܵ����l�������ƣ�
(1)ݔ�딵(sh��)�M���L�ȱ����2�ă缉��(sh��)���Ҳ���С��32��
(2)ݔ�딵(sh��)�Mx�����D(zhu��n)���Ӕ�(sh��)�Mw��횰��p���R��ʽ�惦������(sh��)�M��ʼ��ַ��ĩ3λ������㣻
(3)��(sh��)��(j��)�Ĵ惦��ʽ�����С��ģʽ(Little Endian)��
(4)��(zh��)�����g�ɽ����Д࣬������푑����@���܌���һЩ���r�¼��ò������r푑���

���ʹ�á�DSPF_sp_cfftr2_dit()���r�����]���@Щ���ƣ����п��܌��³����\�Ю�������ˣ��캯��(sh��)��Ч���mȻ�ߣ�������äĿ�ĞE�ã��ڳ����_�l(f��)�r����횸���(j��)���H��r��ͨ���Ժ�Ч��֮�g�M�����ԣ��Ժ�����ʹ�Î캯��(sh��)��
3 TMS320C67x Fast RTS Library��
��DSP�M�Д�(sh��)��(j��)̎��r������һЩ���͵IJ����⣬߀���ڴ�����Ҏ(gu��)�IJ��������������������(sh��)�\�㡢���Ǻ���(sh��)�ȣ��@Щ����Ҳ�Ǻ��M�r�ģ�����@Щ�����Ĵ��aЧ�ʣ�Ҳ���@���������ܛ����Ч�ʡ�TMS320C67x FastRTS Library�����@�ӵ�һ��DSP Lib����ͨ����Lib�ļ��A��include�ļ��A��doc�ļ��A�M�ɡ�����l(w��i)ib�ļ��A��(n��i)�����ļ�fastrts67x��lib(Little Endian)��fastrts67xe��lib(Big Endian)��Դ�ļ�fastrts67x��src��include�ļ��A��(n��i)���^�ļ�fastrts67x��h��recip��h����doc�ļ��A��(n��i)�������ļ���
3��1 TMS320C67x FastRTS Library��ʹ��
TMS320C67x FastRTS Library(���º��QFastRTS Library)��Ҫ����̎��һЩ��Ҏ(gu��)�IJ�����������ͨ����r�£�CCS�ѽ�(j��ng)��һ��RTSLib-rary������@Щ����(���磬��rts6700��lib������һ���m����TMS320C67x��RTS Library�ļ�)����ˣ����Ҫʹ��FastRTS Library���ͱ���ھ��g朽��^�������ڡ�rts6700��lib�������g朽ӡ�fastrts67x��lib(��fastrts67xe��lib)���������ľ��g朽������x헞飺
-l fastrts67x��lib - rts6700��lib�� -l fastrts67xe��lib - rts6700��lib
FastRTS Libraryͬ����Ҫע���^�ļ���ʹ�ã����Ѓɂ��^�ļ��� ��fastrts67x��h���͡�recip��h�������ʹ��FastRTS Library�е����⺯��(sh��)(���Ǻ���(sh��)������(sh��)����(sh��)��)���t��횰�����fastrts67x��h���������ʹ����(sh��)�������t��횰�����recip��h����FastRTS Library��ʹ�÷�ʽ���£�
3��2 ���ܷ���
�քeʹ��FastRTS Library��RTS Library�����һЩ���ò�����ʹ���������߿ɵõ�������������ĕr����ڂ���(sh��)�����w���2����(���еIJ�����̎��ξ��ȸ��c��(sh��))�����ȱ�2�еĔ�(sh��)��(j��)���l(f��)�F(xi��n)����RTS Library��ȣ�F(xi��n)astRTS Library�������˳����Ч�ʡ�

4 DSP Lib�ľ���
���ϣ�����T����ֻ�ܱ��ӵ�ʹ��DSP Lib��ֻҪ��ѭ������Ҏ(gu��)�t������TҲ�����Լ�����һ��DSP Lib������һ����ε�DSP Lib�IJ��E���£�
(1)�½�һ������newLibrary����������O(sh��)�顰Library(��lib)�����Dl��ʾ���¹����O(sh��)��ʾ��D��
(2)������Ч�ʴ��a�ļ�myLibl��a(ch��n)sm��myLib2��a(ch��n)sm��myLib3��a(ch��n)sm������
(3)��myLibl��a(ch��n)sm��myLib2��a(ch��n)sm��myLib3��a(ch��n)sm���������ļ����ӵ�����new Library�У�
(4)���g朽ӹ���new Library��
�������4�������о͕����F(xi��n)���ļ�newLibrary.lib���@�ӣ�һ��DSP Lib�������ɹ��ˡ�����ʹDSP Lib���б����ԣ�ͨ����r�£�ֻ�豣�������е�newLibrary��lib�ļ������������ļ����e��Դ���a�ļ�*��a(ch��n)sm�h�����ܴ�š��@�ӣ��Ñ���ֻ��ʹ�Î��ļ������o�����еõ�Դ���a����Ϣ��
5 �Y(ji��)���Z
������TMS320C67x DSP Library��TMS320C67x FastRTS Library������Ԕ����B������ڳ����_�l(f��)��ʹ��TI DSP Library����������ʹ��TI DSP Library�������ij���Ч�ʵ���ߡ����߀�o���˾���TI DSP Library��һ�����Ì�����
�� �ԣͣӣ������ã������Y(ji��)��(g��u)������
�ԣͣӣ������ã������ǣԣɹ�˾�ã�������ϵ�Уģӣ��е�һ�N���ã�������ϵ�й��е����c���£�
�����M�Ĺ���Y(ji��)��(g��u)������һ�l���������l��(sh��)��(j��)�������ėl��ַ����
���߶Ȳ��еģãУպ�ᘌ����Ã�(y��u)����Ӳ��
��ᘌ��㷨���Z�ԃ�(y��u)����ָ�
�����M�ģɣü��g(sh��)ʹ��ȸ������ֵ���
�ã�������ϵ�Ѓ�(n��i)��Ӳ�����܉K��D����ʾ�����У��У����������㔵(sh��)߉��Ԫ�����̣գ����ɂ����������ۼ������ͣ£����������������˼ӆ�Ԫ�����������ͣ��ã��������������ƣɣ��\������ؿ��]�����Ӌ�㡢�x�惦��Ԫ���ããӣգ����e�m�ϣ֣���������㷨����������Ͱ����λ�Ĵ�����Ƭ���p��ȡ�ң��ͣ�ÿ�C�����ڿɴ�ȡ�ɴΣ�Ƭ�φδ�ȡ�ң��ͣ���ͬ�r�L���ɉKƬ�ϴ惦�^(q��)��Ƭ������ӿڣ��������ڡ����r�����У̡̣��ȣУɽӿڵȡ�
�ԣͣӣ������ã������������c���£�
�������������ڶ��cָ���(zh��)�Еr�g�����ֹ��
�������� �ף������������Ƭ���p��ȡ�ң���
�������� �ף����������� �ף����(sh��)��(j��)�������� �ף���� �ɣ��ϴ惦���g
������ �ף���� �ȣУɽӿڣ���ͨ�^�˽ӿڷ�����c���O(sh��)���M����Ϣ���Q�����O(sh��)��Ҳ��ͨ�^�˽ӿ����d�ģӣг���
��һ���ԄӾ��_�Ĵ��ں�һ���ԣģʹ��ڣ��Ҷ��������˜�ͬ������
���⣬�ã�������ϵ�Уģӣп�ʹ�ãʣԣ��ǽӿ��M���{(di��o)ԇ������ȫ���ƣģӣ��ϵ������YԴ��ʹ�÷���ɿ���
�� ϵ�y(t��ng)�Y(ji��)��(g��u)
�ɣԣͣӣ������ã�������(g��u)�ɵĔ�(sh��)��(j��)�ɼ�̎��ϵ�y(t��ng)�ĽY(ji��)��(g��u)��D����ʾ���ԣģӣО����ģ����У����˳���ң��ͣ������˔�(sh��)��(j��)�ң��ͣ���ͨ�^�����ˡ������ģƣɣƣό���(sh��)��(j��)�͵��ģ��������ˡ������ģƣɣƣό����IJɼ��Ĕ�(sh��)��(j��)�͵��ģӣС��c���Cͨ�^�ȣУɽӿ��M�Д�(sh��)��(j��)���Q�����ӣң��͡��ƣɣƣϡ����ġ��ģ��Ŀ��ƣ��ģӣ�������N��B(t��i)��Ϣ�ī@ȡ���Լ��c���C������һЩ(li��n)ϵ����ͨ�^�ãУ̣ģ��ͣãУ̣ģ팍�F(xi��n)��
�ã�������ϵ�Уģӣ��P(gu��n)�I���ⲿ�ӿ���̖���£�
������������������ַ����
���ģ����ģ�������(sh��)��(j��)����
�����ͣӣԣң£��ⲿ�惦����ȡ�l
�����ɣϣӣԣң£��ɣ��ϴ�ȡ�l
���ң��ף��x����̖
�����Уӣ�������g�x��
�����ģӣ���(sh��)��(j��)���g�x��
�����ɣӣ��ɣ��Ͽ��g�x��
���ңţ��ģ٣���(sh��)��(j��)�ʂ��
���⣬߀�У��ȣϣ̣ġ����ȣϣ̣ģ��ȣ���ϵ�y(t��ng)δ�á�
������ �惦������
����惦���͔�(sh��)��(j��)�惦����ʹ��һƬ�����ˡ������ģӣң��ͣ�����ʹ�ģӣЌ����IJ����M���죬���ٶȵȼ��飱�����ʹ�ã��У�������惦����Ƭ�x�����ģ�����(sh��)��(j��)�惦����Ƭ�x������Ƭ�惦�����x����̖���£�
���ϣţ����������������ͣӣԣң£� ���� �������ң��ף�����
���ףң����������������ͣӣԣң£� ���� ���ң��ף���
���ڸ��ٵ���Ҫ�������ˣأ�������˾�ģأã�����������߉���ãУ̣ģ������أã����������_�����_�����t�飵���(n��i)���У��������Ԫ�����ù��_�����������ھ����̣�ʹ�������кܶ���(y��u)�c��ͨ�^�@Щ��ʩ��ϵ�y(t��ng)����ȴ��ش�ȡ����͔�(sh��)��(j��)�ң��ͣ�Ҳ�����f���惦���x���_�����͡����������������_�����͡�����������
������ �ƣɣƣϿ���
���ڣģ��ƣɣƣϵČ��ͣ��ģƣɣƣϵ��x���ɣãУ̣ģ��a(ch��n)������߉���̞飺
�����ģƣɣƣϣң����������������ɣϣӣԣң£� ���� �������ң��ף� ���� ���ģģң���������
���ģ��ƣɣƣϣף��������������ɣϣӣԣң£� ���� �ң��� ���� ���ģģң�������
���У����ģģң��أ�ָ�ģӣеģ����������������㡣
�ģɣƣɣƣ��Ƀ�Ƭ���������ˡ����������ٶȣ������ģƣɣƣϘ�(g��u)�ɣ����ģƣɣƣ�����ˡ����ڿ�����̖�ĵ����t�ͣƣɣƣϵĸ��٣����ƣɣƣϵĴ�ȡҲ�_������ȴ�������ʹ�ãңУԻ�ңУԣ�ָ��r�����_�����͡�������������
������ �����ĺͣģ�������
�������D(zhu��n)�Q��ؓ؟���ⲿģ�M��̖׃�Q�ɣģӣп�̎���Ĕ�(sh��)�������ǣģӣ��M��̎���Ļ��A(ch��)����ϵ�y(t��ng)�о���ʮ����Ҫ�ĵ�λ�����õ��ǣ����Ͳɘ��ʡ����������ֱ��ʵģ��ģ��������������Ҫ�����ڲ��İ����r��?li��n)Q�ɣ����ͻ��Ͳɘ��ʵģ����ġ����ģ����t���ģӣ����ɵĔ�(sh��)����̖׃��ģ�M���������̖��ݔ����?q��)�ϵ�y(t��ng)�������ֵĿ��ƣ������ˣ��������ٶȵģ��ģ��������������ĺͣģ����Ŀ�����̖���£�
�����ģạ̃˺ͣģ��ạ̃ˣ��քe�ǣ������D(zhu��n)�Q���ͣģ����D(zhu��n)�Q���ĕr�
�����ģƣɣƣϣף����������D(zhu��n)�Q�Ĕ�(sh��)��(j��)������ģƣɣƣ�
���ģ��ƣɣƣϣң��ģģ��ƣɣƣ��x����(sh��)��(j��)�Թ��ģ����D(zhu��n)�Q
���ģ��ƣɣƣϣͣҺͣģ��ƣɣƣϣңԣ����ڣģ��ƣɣƣϵ��������
�����ģƣɣƣϣͣҺͣ��ģƣɣƣϣңԣ����ڣ��ģƣɣƣϵ��������
��������̖���ɣãУ̣ģ®a(ch��n)�����ãУ̣ģ²��õ��ǣأ�������˾�ģأã������������ٶȞ飱������У����������Ԫ�����ھ����̣�������^�ߵ��`���ԡ�ʹ�ã����ͣȣ��ľ����ãУ̣ģ��ṩ�r犣��ɣģӣ�ͨ�^�ɣ��Ͽ���ãУ̣ģ��딵(sh��)��(j��)�Կ��ƣ��ģạ̃˺ͣģ��ạ̃˵��_�P(gu��n)���l�ʣ����ԣɣ��ό��ķ�ʽ�a(ch��n)���ƣɣƣϵ����������̖��
������ �ãУ̣ģ��ͣãУ̣ģµđ���
�����Ͻ�B���Կ���������ϵ�y(t��ng)��߉���ɣãУ̣ģ��ͣãУ̣ģ®a(ch��n)�������⣬��߀�����¹��ܣ�
���ƣɣƣϵ����Р�B(t��i)��̖��ϵ�y(t��ng)�ⲿ����ĸ��N���ƺ͠�B(t��i)��̖���������ˣãУ̣ģ£����ɣģӣ�ͨ�^�ɣ��Ϸ�ʽ�xȡ
���ģӣе��Ă��ⲿ�Дࡢ�Σͣ��Д�B���ãУ̣ģ£���ͨ�^�ɣ��Ͽڌ��r�����Ă���̖�����Ă��Д࣬�����^����`����
���ģӣе�ͨ�ãɣ��Ϲ��_�£ɣϺͣأ��B���ãУ̣ģ������Բ�ԃ��ʽ����푑��ⲿ��̖
�����C���ģӣеď�λ������һЩ�����Ŀ��ƣ����ģӣе�ijЩ��Ϣ���xȡ
���ģӣЌ�����һЩ����·�Ŀ���
������Ӳ���O(sh��)Ӌ�r�������H���õ�Ҫ������ȫ�˽⣬�����Ҫʹϵ�y(t��ng)������������`���ԣ�ʹ�ããУ̣Ŀ����_���@һҪ��ͨ�^��������Ҫ�ĸ��N���ƺ͠�B(t��i)��̖����ãУ̣ģ������ããУ̣ĵĴ������ͬF(xi��n)���ɾ����ԣ��ɸ���(j��)��ͬ��Ҫ���M�ЬF(xi��n)���ģ��Ķ�ʹϵ�y(t��ng)�O(sh��)Ӌ�ijɹ��ʸ������кܴ���`���ԡ�
ϵ�y(t��ng)��ʹ���˃�Ƭ�ãУ̣ģ����]����һƬ�������ģãУ̣Ĵ��棬�dz���ϵ�y(t��ng)���ܵĿ��]�����惦���ͣƣɣƣϵ��x����̖��Ҫ�^�͵����t�ſɝM����ȴ���Ҫ���������ģãУ̣����t���҃r��ߣ�����ãأã��������M��ϵ�y(t��ng)���ٶȵ�Ҫ���ãأã����������M��ϵ�y(t��ng)���s߉��������Ҫ��
������ �ȣУɽӿ�
�ģӣп�ʹ�ãȣУɣ��ȣ��� �У��� �ɣ��������壠�ӿڷ�����c���O(sh��)�����̎�������Q��(sh��)��(j��)���������������~����������������ͣȣ����l�ģ������ã��������ԣ�ͨ���ٶ������_�����ͣ����ңã�������ϵ�Уģӣ�ͨ�^ij�N�B����ʽ�������ãȣУɽӿ����d���Ķ�ʹϵ�y(t��ng)���и�����`���ԡ��ȣУɽӿڵĿ�D��D����ʾ���УȣУɣ����ȣУɵ�ַ�Ĵ��������ȣУɣģ���(sh��)��(j��)�Ĵ��������ȣУɣã����ƼĴ������������������Ĵ��������O(sh��)�����ͨ�^�@Щ���üĴ����c�ȣУ�ͨ�š��ڣã������ģ����˃�(n��i)���ң����У��У������ڣȣУɴ惦�K��ϵ�y(t��ng)��D��D����ʾ���ȣģ����ȣģ��ǣ�λ��(sh��)��(j��)����ֱ���B�����O(sh��)��Ĕ�(sh��)��(j��)���ϣ��ȣãӞ�Ƭ�x��̖���ȣģӣ��ͣȣģӣ��锵(sh��)��(j��)�i����̖�������O(sh��)��Ĵ�ȡ���ڿ��Ɣ�(sh��)��(j��)�Ă�ݔ��һ���B�����O(sh��)��Ĕ�(sh��)��(j��)�xͨ���ȣң��כQ����ǰ�������x߀�nj����ɸ���(j��)���O(sh��)��ľ��w��r�Q���c�ηN��̖���B���ȣãΣԣ̣������������O(sh��)���x���ȡ�ȣУɵ���һ���Ĵ����͌��Ĵ����Ĵ�ȡ��ͣ��B�����O(sh��)��ĵ�ַ�������ڣȣУɼĴ����ǣ���λ�����ȣУ��c���O(sh��)��H�ԣ�λ��(sh��)��(j��)�����B������ãȣ£ɣ̛Q����ǰ��ȡ����һ���ֵĵ�һ߀�ǵڶ��ֹ�(ji��)���B�����O(sh��)��ĵ�ַ����
���ȣУ��M�в���������Ҫ����������ȣУɣã�Ȼ��Ҫ��ȡ�ĵ�ַ����ȣУɣ�������ȡ�ȣУɣģ��ͿɏģȣУɴ惦�K�x��(sh��)��?q��)��?sh��)��(j��)����ȣУɴ惦�K�����⣬߀���x��ȣУɣ��Ԅ����ӷ�ʽ������ʼ��ַ����ȣУɣ��ɲ��ٲ����ȣУɣ���ÿ��ȡһ�Δ�(sh��)��(j��)����ַ�����ԄӼ�һ��������ӿ��˴�ȡ�ٶȡ�
�ڱ�ϵ�y(t��ng)�У����O(sh��)���ǣ��ͣģ�������(g��u)�ɵ�Ƕ��ʽϵ�y(t��ng)�����ͣ��c�ȣУɵ��B����D����ʾ�������Ͻ�B���Կ�����ʹ�ãȣУ�Ҳ���c�УÙC�ģɣӣ�����������B�ӣ��ãУÙC�������O(sh��)�䣬ͨ�^�УÙC��ģӣ����d������ɸ��N���ܡ�
Ҫʹ�ãȣУ����d����ֻ���ڣģӣЏ�λ�r������ͨ�^�ȣУɽӿڌ���ȣУɴ惦�K�ģ��أ��������_ʼ�Ĵ惦�^(q��)��������늏�λ���һ�Εr�g���ȣɣΣԹ��_����̖�����ɣΣԣ����_���ģӣ��ڣ£��������Йz�y���͕��Ԅ����D(zhu��n)�����أ�������̎�_ʼ��(zh��)�С�
�� ϵ�y(t��ng)�������̼��O(sh��)Ӌע�����
ϵ�y(t��ng)ͨ�^���H�yԇ���\���ٶȞ飴���ͣɣУӣ�����͔�(sh��)��(j��)�惦�������Уɣ��Ͽڶ���ȫ���\�У�������(w��n)���ɿ����乤���������£�
����������(j��)Ҫ���ģӣг����{(di��o)ԇͨ�^��
��������λ�ģӣУ��������O(sh��)��ͨ�^�ȣУɽӿ���ģӣ����d����
��������λ��̖ʧЧ���ģӣ������O(sh��)��Ŀ������_ʼ������
����ϵ�y(t��ng)�������^�ߵ��l���£��ãУ՞飴���ͣȣ�������O(sh��)��һ��飲���ͣȣ�����ߞ飴���ͣȣ����������ϵ�y(t��ng)�O(sh��)Ӌ�У����ע����lӰ푡�
���ȣ�ϵ�y(t��ng)Ҫ�M�����Σ�Ҫ�x���������������b��Ԫ��������ʹԪ����(sh��)���١��w�eС��������̖���䲢�����ڲ�����
��Σ����O(sh��)Ӌ�Уã°�r��Ҫ�����ČӰ壬���g�Ɍ����Դ�͵أ������һЩȥ����ݡ������r�����ã����ȵĹՏ����^��Ҫ�M���١���(sh��)��(j��)�͵�ַ��óɽM�������Խ��͌�������̖��Ӱ푡�һЩ�P(gu��n)�I�Ŀ��ƾ�����惦���x����̖�ͣƣɣƣ��x����̖����������߅�ӵؾ����o���e�ǣƣɣƣϵ��x����̖�������䌦�ɔ_�e���У�Ҫ�eע�⡣��һЩ�^�L���������ɴ���һ����������С����ӽK��ƥ���ԜpС���䡣
�� �ã�������ϵ�Уģӣе�ܛ�����̺��{(di��o)ԇ
�ã�������ϵ�Уģӣеľ��̹��ߣ��У��Z�ԺͅR���Z�ԃɷN�����R���Z�����ЃɷNָ���һ�N��ӛ��ָ����ͣ�������� �ɣ������������� �ӣ��������ƣ��������ąR���Z�ԣ�һ�N�д���(sh��)ָ�������������� �ɣ������������� �ӣ����������ڣ��Z�ԣ�ʹ��������ӛ��ָ�����ܶࡣ
���H�����У�һ�㶼�ǣúͅR����Ͼ��̣���Ͼ��̵ķ������ɲ�醣ã�������ϵ�Уģӣе��փԵõ����ԣɹ�˾߀�ṩ��һ���\�Ў죨�ң��������� �̣�⣠���ãԣɹ�˾�ģʣԣ����{(di��o)ԇ���M���{(di��o)ԇ�r���ڣģӣг������{(di��o)���\�Ў�ĺ���(sh��)�����Դ��_�УÙC�ϵ��ļ��@ȡ��(sh��)��(j��)����?q��)��ģӣеĔ?sh��)��(j��)����УÙC�������ļ�����ͨ�^�УÙC�I�P��ģӣЂ��f��Ϣ�Ͱl(f��)�������֮�����Ԟ��{(di��o)ԇ����O��ķ��㡣
�ڱ�ϵ�y(t��ng)�У����ڼ��У����ģ����Уģ�������(g��u)����һ���]�h(hu��n)���l(f��)���ա������ɣģ�������ģ�M���Σ��ɣ����Č��r�ɼ����ɣģӣ�̎�������㷨���O(sh��)Ӌ���{(di��o)ԇ�Ɏ����ܴ�Ď�����
]]>����̖�o̎���ڣ�ͬ�rҲ��������������Ϣ�����ճ������a(ch��n)�����У��҂���������̖������Ժ����^�̣��õ��҂���Ҫ�ĽY(ji��)�����S�� DSPоƬ���ԃr�Ȳ���������ʹ DSP���ԏ�܊���I(l��ng)����չ�������I(l��ng)������ TI��˾ DSP5000ϵ�Џ�������l���s�������Z�����õõ����^��İl(f��)չ����ˣ����� DSP�����ɼ�ϵ�y(t��ng)���O(sh��)Ӌ�c�_�l(f��)������Ҫ�ĬF(xi��n)�����x��
1ϵ�y(t��ng)���w��B
ԓϵ�y(t��ng)��Ҫ�����ڹ��I(y��)���a(ch��n)�У�ͨ�^�ɼ�������̖�c��(sh��)��(j��)���еĔ�(sh��)��(j��)����^����z�y���a(ch��n)�O(sh��)����\�Р�B(t��i)�ȡ���ϵ�y(t��ng)��Ҫ�֞����ׂ����֣��ƽ�D(zhu��n)�Q�·�� AD�D(zhu��n)�Q�·���o�B(t��i)�惦�c�ӑB(t��i)�惦��USB�ӿ��Լ� JTAG���֡�
ԓϵ�y(t��ng)ͨ�^�ɼ�����̖��z�y��е���Ѽy���ܺ϶ȵȡ��� DSP����̎�픵(sh��)����̖�������c USB���ق�ݔ��(sh��)��(j��)�������Y(ji��)��������ʹ������ڹ��I(y��)���a(ch��n)����ԓϵ�y(t��ng)����Ҫ�O(sh��)ӋĿ�ġ�ϵ�y(t��ng)�x���� TI��˾��TMS320VC5402����ԓ�K PCB�� CPU������ PHILIPS��˾�� PDIUSBD12����ӿ�оƬ��ʹ�� USB1.1�f(xi��)�h�M�� DSP�c��X��ͨ���� 2Ӳ���O(sh��)Ӌ˼������� ��������̖�Ƿ����� 20-20kHz��ģ�M��̖������������Ҫ����������ԓ����̖��������Ҫ�M���D(zhu��n)�Q��ʹ����̖��ģ�M��̖׃?y��u)�?sh��)����̖��֮��ͨ�^�������a(ch��n)����ԭ���Ҏ(gu��)�ɣ����ñ��y��̖�����c������ԣ��z�y�����w������̖���ڙz�y���������l����̖����əz�y���r����̖�ķe��ƽ�����xɢ��̖��Ӌ��(sh��)���g(sh��)�����Йz�y�ȷ�����
���� 5402Ƭ��(n��i)�� ROM�� DRAM�YԴ���ޣ�����ԓϵ�y(t��ng)��Ҫ�ⲿ�惦�O(sh��)�䣬���O(sh��)Ӌ�x��һƬ SRAM�����o�B(t��i)�惦����һƬ FLASH����ӑB(t��i)�惦�O(sh��)�䡣5402�� CPU늉��� 3.3�������O(sh��)늉��� 1.8��������ԓϵ�y(t��ng)߀��Ҫһ����늵��Դģ�K�����Ԍ�һ���ݔ��늉� 5���D(zhu��n)���� 3.3�c 1.8����늉��� DSP��늣�ԓ 5V늉�߀�ɞ�� DSP����������O(sh��)�乩늡�
DSP�cӋ��C��ͨ�ţ�ͨ������ USB��RS232��PCI�� ISA���ȷ�ʽ��RS232����Ҫȱ�c�ǣ��ٶ�������֧�֟��Σ� PCI�c ISA������Ҫȱ�c�ǣ���Ӌ��C���۔�(sh��)������ַ���YԴ�����ƣ��ɔUչ�Բ������ USBͨӍ����Ҫ��(y��u)�c�����ǂ�ݔ�ٶȿ죬֧�֟��Σ�ռ���YԴ�٣��ɔUչ�ԏ���ԓ�O(sh��)Ӌ���� USB�ӿ�оƬֱ���c DSP���B��ͨ�^ DSP�ij���?q��)��F(xi��n) USB�ąf(xi��)�h�����ă�(y��u)�c���ǿ��Ա��ϔ�(sh��)��(j��)���Q���ٶȡ��C�ϣ��ڱ�ϵ�y(t��ng)�У��ׂ������h(hu��n)��(ji��)���ǣ��ƽ�D(zhu��n)�Q�·���� 5V�Դ�D(zhu��n)�Q�� 3.3V�c 1.8V���քe�� DSPоƬ��Ƭ�����O(sh��)�Լ� CPU��늣� AD��̖�D(zhu��n)�Q�·�������������յ���ģ�M��̖�D(zhu��n)�Q�锵(sh��)����̖���� DSP�M��̎������̖�Ĵ惦�·������ DSP̎������̖����̖��ݔ�·������(j��ng)�^̎������̖�ς�����X�������·�����ڜyԇ DSPоƬ�����w�ܘ�(g��u)��D 1��ʾ��
3ģ�K��B
3.1 DSP
1�� DSP���g(sh��)����
��(sh��)����̖̎���������Q DSP���nj��I(y��)�M����̖̎����оƬ��Ŀǰ��ͨ�š��Կ��I(l��ng)����ЏV���đ��á�����Ϣ�YԴ����S���Ľ��죬��(sh��)�ֻ��̶��ѽ�(j��ng)Խ��Խ�ߡ��� DSP�����@һ���g(sh��)����Ҫ�M�ɲ��֣����҂��������ѽ�(j��ng)�a(ch��n)����Խ��Խ��̵�Ӱ푡��ԏ� 1978�� AMI��˾�l(f��)���ˡ���̎���O(sh��)�䡱�_ʼ���Ļ��� Harvard�Y(ji��)��(g��u)��ʹ�ò�ͬ��(sh��)��(j��)�c�����ĵ�һ��ͨ��DSP�����M���˸��M�ĵڶ���������ͨ��DSP���ٵ������� GPP�Y(ji��)��(g��u)�ĵ�����DSP�������DSP�İl(f��)չڅ���ѽ�(j��ng)څ���ڻ�ϽY(ji��)��(g��u)��DSP�a(ch��n)Ʒ�cӋ��C֮�g�IJ�e�ѽ�(j��ng)Խ��Խģ�����ڔ�(sh��)�ֻ��r�������£�DSP�ѳɞ���N��Ӯa(ch��n)Ʒ���I(l��ng)��Ļ��A(ch��)������������늙C���ơ����R�e�c�D���R�e�I(l��ng)���еđ��Ät�Ǹ���V����
2�����ɼ�ϵ�y(t��ng)�в��õ� DSP
��ϵ�y(t��ng)�� DSP���õ��� TI��˾�� TMS320VC5402�����º��Q 5402��������������_ 100 MIPS����������и��M�Ĺ���Y(ji��)��(g��u)��������������һ��ָ�����ڃ�(n��i)��� 32x32bit�ij˷��������Ѹ����ɔ�(sh��)�W�\����õij˼��\�㡣���� 4�l��ַ������3�l 16λ��(sh��)��(j��)�惦�������� 1�l����惦�������� 40λ���g(sh��)߉��Ԫ (AIU)��һ�� 17��17�˷�����һ�� 40λ���üӷ�����8���o���Ĵ�����һ��ܛ���������Sʹ�������M�Ķ��c DSP�� C�Z�Ծ��g������(n��i)�ÿɾ��̵ȴ���B(t��i)�l(f��)�������i��h(hu��n)(PLL)�r犮a(ch��n)�������ɂ���ͨ�����_���пڡ�һ�� 8λ�����c�ⲿ̎����ͨ�ŵ� HPI�ڡ�2�� 16λ���r���Լ� 6ͨ�� DMA���������e�m��늳ع���O(sh��)�䣮
]]>CCS��Code Composer Studio�����a�{(di��o)ԇ����һ�N�����_�l(f��)�h(hu��n)��(IDE��Integrated Development Environment)�� CCS��һ�Nᘌ��˜�TMS320�{(di��o)ԇ���ӿڵĽ���ʽ������CCSĿǰ��CCS1.1 CCS1.2 CCS2.0��������ͬ�İ汾��ÿ���汾����CC2000��ᘌ�C2XX��
CCS5000��ᘌ�C54XX��CCS6000��ᘌ�C6X����������ͬ����̖���҂���ʹ�õ���CC2000��1.2�İ汾���@�����f����CCS��һ�І��}���ǻ���CC2000��ӑՓ���������汾��ʹ�����e���Ǻܴ�Ո�����������P(gu��n)�Y����
1.CC2000�����c
CC2000�����������ԣ�
lTI���g������ȫ���ɵĭh(hu��n)��
CC2000Ŀ�˹���ϵ�y(t��ng)����(n��i)�����������е��{(di��o)ԇ�ͷ�������������һ��Windows�h(hu��n)���С�
l��C��DSP�R���ļ���Ŀ�˹���
Ŀ�˾������������ļ������P(gu��n)��(n��i)�ݵĸ�ۙ����ֻ�����һ�ξ��g�и�׃�^���ļ����¾��g���Թ�(ji��)ʡ���g�r�g��
l���ɵľ����{(di��o)��C��DSP�R�����a
CC2000�ă�(n��i)������֧��C�ͅR���ļ��ĄӑB(t��i)�Z�������@ʾ��ʹ�Ñ��ܺ�������x���a�ͮ����l(f��)�F(xi��n)�Z���e�`��
l�����{(di��o)ԇ�r�ĺ��_��
�Ñ���ʹ�þ��g���ͅR�����r�]�б�Ҫ�˳�ϵ�y(t��ng)��DOS�h(hu��n)���У����CC2000���Ԅӌ��@Щ�����b�d�����ĭh(hu��n)���С����䴰���У��e�`�������@ʾ��ֻҪ�p���e�`�Ϳ���ֱ�ӵ��_���e̎��
l�ں��и��c�����{(di��o)ԇ������(PDM)��ԭ�е�MS������֧�ֶ�̎������CC2000�� Windows95��Windows-me��֧�ֶ�̎������PDM���S����������o���еĻ����x���̎������
l���κ��㷨�c�^����̖�ĈD�δ���̽�
�D���@ʾ����ʹ�Ñ��܉��^��r������l�����̖�������l��D��F(xi��n)FT�����C��(n��i)��(zh��)�У��@�ӾͿ����^�������dȤ�IJ��ֶ��o횸�׃����DSP���a���D���@ʾҲ����ͬ̽��B�ӣ���ǰ�@ʾ���ڱ����r��̽ᘱ�ָ�����@�Ӯ����a��(zh��)�е��_ԓ�c�r���Ϳ���Ѹ�ٵ��^�쵽��̖��
l�ļ�̽����㷨̎ͨ�^�ļ���ȡ�������̖��(sh��)��(j��)
CC2000���S�Ñ��PC�C�x��?q��)���̖���������nj��r���x��̖���@�Ϳ�������֪�����Ӂ������㷨��
l�D���
CC2000�ĈD�η�����������h(hu��n)�����Ǽ��ɵġ�
l�ں��_(ϵ�y(t��ng)����)��(zh��)���Ñ���DOS����
�Ñ����Ԉ�(zh��)��CC2000�е�DOS��������ݔ������ˮ��ʽ�͵�CC2000��ݔ�����ڡ������S�Ñ��������ɵ�CC2000��
l���g(sh��)��B(t��i)�^�촰��
CC2000�Ŀ�ҕ�������S�Ñ��I��C���_ʽ�����P(gu��n)׃�����Y(ji��)��(g��u)����(sh��)�M��ָᘶ��ܺܺ��ε��f�w�Uչ�͜p�٣��Ա��M����s�Y(ji��)��(g��u)��
l����(sh��)�ֽⴰ��
���S�Ñ��x��鿴���ɴ���(sh��)���_ʽ��C��ʽ���Ķ������x�������a��
lĿ��DSP�ϵĎ���
DSP�Y(ji��)��(g��u)�ͼĴ����ϵ��ھ���������ʹ�Ñ����ز鿴���g(sh��)�փ���
l�Ñ��Uչ
�Uչ�Z��(GEL)ʹ���Ñ����Ԍ��Լ��IJˆ�헼ӵ�CC2000�IJˆΙ��С�
l��ȫ���_�l(f��)�h(hu��n)��
CC2000��TI�ľ��g�����R�������B�ӹ��߶����ɵ������_�l(f��)�h(hu��n)���С��Ñ����ԏIJˆΙ����x��TI�Ĺ��ߣ������Կ���ֱ����ˮݔ�������ڵľ��g�Y(ji��)����ͬ�r�����e��Ϣ�����@ʾ���p�����e��Ϣ���Դ��_Դ�ļ������ͣ�ڳ��e̎������DOS��TI�Ĺ����Ƕ��΄յġ�����Windows�h(hu��n)���У��Ñ����Ժܷ����ͬ�r�����{(di��o)ԇ�����gԴ�����a���g�����Ը�ۙһ���Ŀ�����е��ļ������P(gu��n)��(n��i)�ݡ��Ñ������x���g�����ļ�����?q��)������ļ�����һ���Ŀ�У��������Ŀ���ھ��g�����R���������B�����x���������ʹ�õČ�Ԓ��
CC2000�Ŀ�ҕ������ʹ�Ñ��܉�����������s�ĽY(ji��)��(g��u)��ֻҪ����˷������P(gu��n)׃��̎����ENTER�I���T�电(sh��)�M���Y(ji��)��(g��u)��ָᘵ�׃���Ϳ����f�w�����ӻ�p�١����⣬���ӵ���ҕ���ڵ�׃��Ҳ����ͨ�^�p��ԓ׃��������C���_ʽ��GEL����(sh��)Ҳ�������ӵ���ҕ���ڡ���GEL����(sh��)���ӵ���ҕ���ڣ��Ϳ�����ÿ�����c̎��(zh��)�С���GEL����(sh��)�����Ԉ�(zh��)�и����s���΄գ����Y(ji��)��ݔ�������ڡ�
̽����S�Ñ��^����̖�����㷨�ϼ������ȡ��(sh��)��(j��)���������B�ӵ��Y(ji��)��(g��u)�c��惦���g�����_�㷨���ָ���c�r�����B�ӵ���̖̽ᘾ͕���Ŀ��DSP����ȡ����(sh��)��(j��)���@ʾ��������ļ�ָͬ���c���B����(sh��)��(j��)�͕���ָ���Ĵ惦���g�c�ļ��g��ݔ������һ�Y(ji��)������(zh��)�о��_ʼ���@�N����ʹ���_�l(f��)���܉�ܿ���^�쵽Ŀ�˃�(n��i)�沢ͨ�^�ļ����ض����㷨�c���ӻ���ȡ��(sh��)��(j��)�����ÄӮ����ԣ��_�l(f��)�߿���ͨ�^ʹ��PC�C�űP�еČ���̖���µ��^��͈�(zh��)����̖�������ø�׃Դ���a��]]>
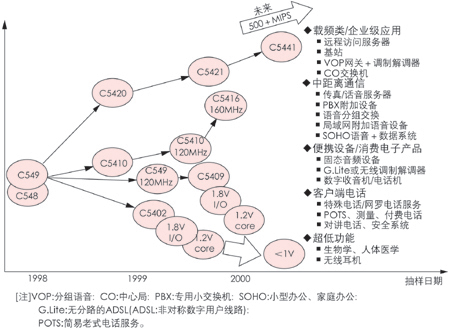
�D1 TMS320C5000���ܰl(f��)չ��r�������I(l��ng)��
TMS320ϵ�е�ͬһ��оƬ������ͬ��CPU�Y(ji��)��(g��u),������(j��)�Ј��IJ�ͬ��Ҫ,�γ��µĴ惦���c���O(sh��)�IJ�ͬ�M��,�a(ch��n)���˶�N����������
TMS320C54x�P(gu��n)�I����
�D2��C54x���ܽY(ji��)��(g��u)�D,������Ҫ�������£�
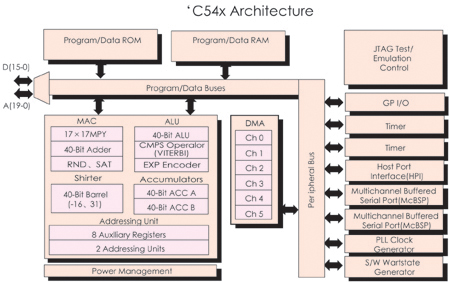
�D2 TMS320C54x���ܽY(ji��)��(g��u)��D
�� CPU
���M�Ķ࿂���Y(ji��)��(g��u)��һ�M������PAB��PB��,���M��(sh��)��(j��)������CAB��CB,DAB��DB,EAB��EB��
40λ�Ĕ�(sh��)�W߉��Ԫ��ALU��������40λ��Ͱ����λ�Ĵ����̓ɂ�������40λ�ۼ���
17 17λ���г˷�����40λ���üӷ���,��������ɳ˷�/�ۼ�(MAC)
�m��Viterbi�\��ı��^���x�惦��Ԫ��CSSU��
ָ��(sh��)���a��,���چ����ڃ�(n��i)Ӌ�㣨40λ���ۼ����Д�(sh��)ֵ��ָ��(sh��)
�ɂ���ַ�a(ch��n)����,�����˂��o���Ĵ����̓ɂ������g(sh��)��Ԫ
�� �惦��
�Ɍ�ַ�惦���g�_192K�֣�����(sh��)��(j��)��I/O��64 64bit��,C548߀�ɔUչ����惦����8���֣�
����C5400оƬ�惦��
�� Ƭ��(n��i)���O(sh��)
ܛ���ɾ��̵ȴ���B(t��i)�a(ch��n)����
�ɾ��̵ĉK���Q
Ƭ��(n��i)�i��h(hu��n)�r犮a(ch��n)����
��ֹ�ⲿ�����Ŀ��ƙC��
�� ָ�
�؏͆Ηlָ���c�؏�ָ��K
&nbs
p; �惦���K�Ƅ�ָ��32λ��(sh��)�\��ָ��
��ͬ�r�xȡ2��3��������(sh��)��ָ��
���в��б���Ͳ��м��d�����g(sh��)ָ��
�l������ָ��
�� ���Ŀ���
IDLE1��IDLE2��IDLE3ָ��ɿ������M�뽵����ģʽ
�ɿ����Ƿ�ݔ��CLKOUT��̖
�� IEEE�˜ʵ�1149.1߅�����߉�ӿ�
TMS320C54x�Y(ji��)��(g��u)����
''C54x������̎����CPU���惦����Ƭ��(n��i)���O(sh��)�M��,���ù���Y(ji��)��(g��u),�Ъ����ij�����g����(sh��)��(j��)���g��I/O���g���D3��''C54x�ă�(n��i)��Ӳ����D��
�����е�''C54x�������f,�D���°벿��ʾ������̎���Ԫ��CPU����ͨ�õġ�
�����Y(ji��)��(g��u)
һ�M������PAB��PB�������M��(sh��)��(j��)����CAB��CB,DAB��DB,EAB��EB������(n��i)��������(li��n)ϵ������
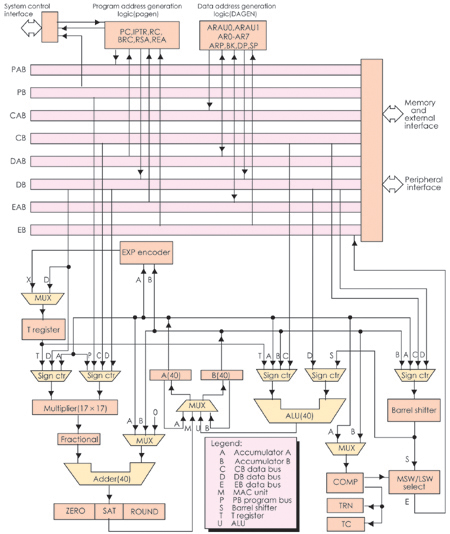
�D3 TMS320C54x��(n��i)��Ӳ����D
PB- ����,���ͳ�����a����ڳ�����g�Ĕ�(sh��)��(j��);
CB��DB��EB- ��(sh��)��(j��)����,�B��CPU����(sh��)��(j��)��ַ�a(ch��n)��߉�������ַ�a(ch��n)��߉��Ƭ��(n��i)���O(sh��)���惦���ȸ�����;
CB��DB- ���͏Ĵ惦���x���Ĕ�(sh��)��(j��),�����x������ʹ�õĔ�(sh��)��(j��)����;
EB-������惦������Ĕ�(sh��)��(j��),��"��"����ʹ�õĔ�(sh��)��(j��)����;
PAB��CAB��DAB��EAB- �������ĵ�ַ����;
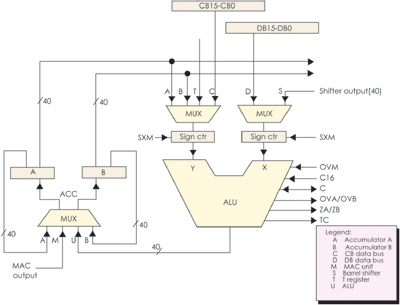
�D4 ALU���ܿ�D
����̎���Ԫ��CPU��
ALU�����g(sh��)߉�\���Ԫ
��Ҫ��40λALU�̓ɂ�40λ�ۼ���(ACCA��ACCB)�M��,��D4��ʾ��
&
nbsp; ALU�̓ɂ��ۼ����Á����40λ���M���a�a�����g(sh��)�\��,Ҳ����ɲ����\�㡣����B(t��i)�Ĵ惦��ST1��C16λ��1�r,�����ɂ�16λALU,ͬ�r��Ƀɂ�16λ�\�㡣ݔ�룺
16�����(sh��);
���Ԕ�(sh��)��(j��)�惦����16λ��(sh��);
���ԕ�����T��16λ��(sh��);
���Ԕ�(sh��)��(j��)�惦���x���ăɂ�16λ��(sh��);
���Ԕ�(sh��)��(j��)�惦���x����һ��32λ��(sh��);
�����ۼ�����A��B����40λ��(sh��);
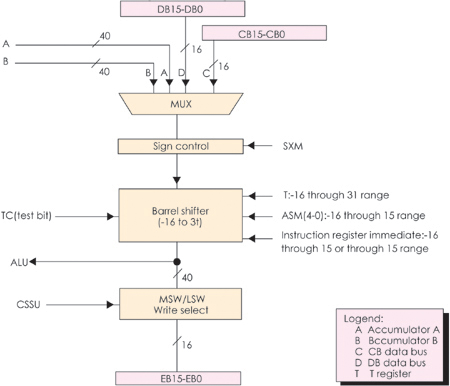
�D5 Ͱ����λ�����ܿ�D
ݔ����ALU��40λݔ���������ۼ���A��B��
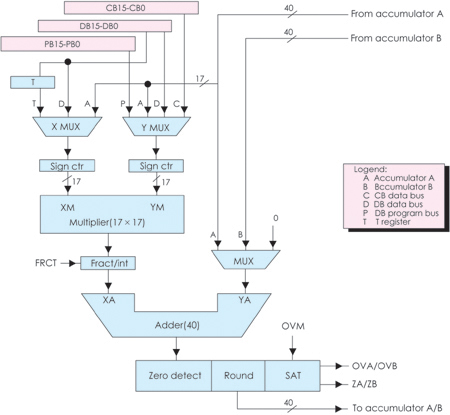
�D6 ��/��ģ�K���ܷ���D
Ͱ����λ������ݔ�딵(sh��)��(j��)����0��31λ������0��16λ,��(j��ng)��������(sh��)�ֶ��ˡ�λ��ȡ���Uչ���g(sh��)��������o�Ȳ����� ݔ��40λ�������ۼ�����(j��ng)DB��CB�� ��(sh��)��(j��)�惦��;
ݔ��40λ���B��ALU��(j��ng)EB�B����(sh��)��(j��)�惦��;
����λ��(sh��)��ָ������λ�ֶΡ�ST1��ASM�ֶλ�T�Ĵ���ָ����λλ��(sh��)�Q����
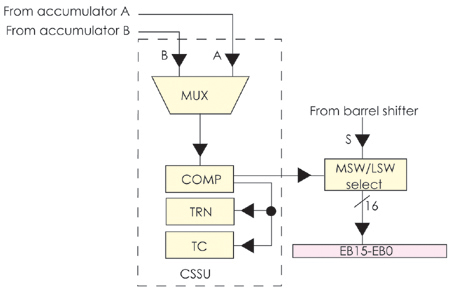
�D7 ���^���x���c�����Ԫ��CSSU�����ܿ�D
��/��ģ�K���ɳ˷������ӷ�����ݔ�딵(sh��)��(j��)�ķ�̖����߉��С��(sh��)����߉����z�y�����롢���/�߉��16λ����Ĵ���T�ȽM�ɡ��˷�����ALU��һ��ָ�����ڃ�(n��i)��ͬ���(17 17�a�a)��/�ӣ�40λ���\��,�ҿɲ��е���ALU�\��,�@Щ���ܿ��Á���Euclidean���x��LMS�V���ȏ��s�\�㡣��/��ģ�K���ܷ���D��D6��ʾ��
���^���x���c�����Ԫ(CSSU)����������ۼ����ĸ�λ�ֺ͵�λ��֮�g�����ֵ���^(CMPSָ�����һ���������Ã�(y��u)����Ƭ��(n��i)Ӳ���YԴ��ɔ�(sh��)��(j��)ͨ�š�ģʽ�R�e���I(l��ng)���н�(j��ng)���õ���Viterbi�����\�㡣
&
nbsp;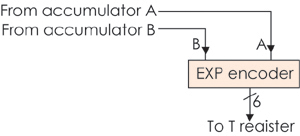
�D8 ָ��(sh��)���a��
ָ��(sh��)���a��������֧�ֆ�����ָ��EXP�Č���Ӳ��,��D8��ʾ��
�ۼ����Д�(sh��)ֵ��ָ��(sh��)ֵ,�Զ��M���a�a��ʽ(-8��31)����ڕ�����T��;
CPU��B(t��i)�Ϳ��ƼĴ�����
''C54x����3��16λ��B(t��i)�Ϳ��ƼĴ�����PMST��ST0��ST1���������Ǵ惦��ӳ��Ĵ���,���Է���،��딵(sh��)��(j��)�����ɔ�(sh��)��(j��)�惦�����������d��
��(n��i)���惦��
��''C54x�Ĵ惦���֞������ɪ����x��Ŀ��g��������g����(sh��)��(j��)���g��I/O���g;
��''C54x��Ƭ��(n��i)�惦������ROM��RAM,����RAM�ֿɷ֞�SARAM��DARAM��SARAM��Ό�ַ�Ĵ惦��,DARAM���p��ַ�Ĵ惦��(һ���ڃ�(n��i)�����L���ɴ�)��
ROMһ�����óɳ���惦���g,���ڴ��Ҫ��(zh��)�е�ָ�ϵ��(sh��)���ȹ̶�������(sh��)��Ҳ���Բ��ֵذ��ŵ���(sh��)��(j��)�惦���g,��PMST�Ġ�B(t��i)λ ��DROM�Q��;RAM һ�㰲�ŵ���(sh��)��(j��)�惦���g,��ň�(zh��)��ָ����Ҫ�õĔ�(sh��)��(j��)����Ҳ�����ŵ�������g,��PMST�Ġ�B(t��i)λOVLY�Q������ͬ''C54xϵ�Ѓ�(n��i)���惦�����ø�����ͬ��
''C54x�Č�ַ��ʽ
TMS320C54x��ָ����ܺ���1���惦��������(sh��)��ָ���f������Smem��ʾ��,Ҳ������2���惦��������(sh��)��ָ���f������Xmem��Ymem��ʾ��,�քe�Q��δ惦��������(sh��)���p�惦��������(sh��)���δ惦��������(sh��)��7�N��ַ��ʽ,�����ǣ�
������ַ�� ������(sh��)(����(sh��))����ָ����;
�^����ַ�� ָ���к��в�����(sh��)��16λ��ַ;
�ۼ�����ַ�� ������(sh��)��ַ���ۼ�����(A);
ֱ�ӌ�ַ�� ָ���к��в�����(sh��)��ַ�ĵ�7 λ;
�g�ӌ�ַ�� ������(sh��)�ĵ�ַ���o���Ĵ�����,֧�ֵ�λ��?q��)�ַ��ѭ�h(hu��n)��ַ�ȹ���;
�惦��ӳ��ļĴ�����ַ��
�L���惦��ӳ��Ĵ���,
�ֲ�Ӱ�DP��SP;
�ї���ַ�� �L���ї�;
�p�惦��������(sh��)֧��һЩ����ָ�
��MAC��FIR�ȏ��sָ�
''C54x������ָ����ˮ��
&nb
sp; ''C54x CPU��ָ����ˮ��������,ÿ�����������lָ���ڹ���,����̎��������(zh��)���^�̵IJ�ͬ�A��,��D9��ʾ�� 
�D9 ��ˮ����ͬ�����A�β�����(n��i)��
��ˮ���Ĺ���ȫ�������ָ���B�m(x��)��(zh��)�Еr��������r����D10 ��ʾ��
�D10 ��ˮ�����������r���I(y��)��r
]]>�Ұl(f��)�F(xi��n)�ڇ���(n��i)�oՓ�ڹ�˾���У�S��ط����˼ӿ��_�l(f��)����������һ���a(ch��n)Ʒ�_�l(f��)�֞�Ӳ����ܛ���ɂ������������֣��ɲ�ͬ������ɡ��@�ھ���һ�����g(sh��)�������A(ch��)�Ĺ�˾���ɿ��O(sh��)Ӌ���y(t��ng)һҎ(gu��)���f(xi��)�{(di��o)�����΄ղ�����ɵ���r���ǿ��еģ�Ҳ�Ƿ��ϬF(xi��n)���a(ch��n)Ʒ�_�l(f��)Ҏ(gu��)�ɵġ������ڸ�У�ˆT�����Ӻܴ��о�������Ч���Еr�g�̡ܶ����A(ch��)��S���о����r����ۡ���衢���O�ܵķ���x�Ͷ������y����Ҳ���@���^���ģ��������fϵ�y(t��ng)Ҏ(gu��)���O(sh��)Ӌ�ˣ��r���S���ϰ��Լ�Ҳ��̫�����������Լ����΄գ����������וrҲ���I(y��)�ˡ����S���У��DSP������һ���㷨�ӵ��Լ�����������ڰ�������һ�£������_��Ч���Ϳ����ˣ����ڿɿ����Ǵ�Ҫ�ģ��a(ch��n)�I(y��)���o��Մ���@�ѽ�(j��ng)�㲻�e���ˡ�
�䌍���X��һ��ϵ�y(t��ng)����ɣ�ϵ�y(t��ng)��Ҏ(gu��)��������Ҫ�ģ���Ҏ(gu��)���r��Ӳ���O(sh��)Ӌ��֪�R���J�R�ǛQ���Եģ���������֪��ʲô�ǿ��еģ�ʲô�Dz����еģ�����ͬ�r����ܛ���O(sh��)Ӌ�����r���Ϳ��Ժ����ķ���ϵ�y(t��ng)���ܣ����ʹ��VHDL�M��ϵ�y(t��ng)�О���������ϵ�y(t��ng)���܄��֡��� ϵ�y(t��ng)�ӽY(ji��)��(g��u)�O(sh��)Ӌ�@�ӵ�������µ��O(sh��)ӋҎ(gu��)�����̣��ɞ�ϵ�y(t��ng)�O(sh��)Ӌ���ҡ��Ŀ��(j��ng)������tֻ��Ӳ�����̎���ܛ�����̎����oՓ��51��196��߀��DSP�����@�ӡ�
����քeՄՄ�Ҍ�Ӳ����ܛ���O(sh��)Ӌ�ĸ���
Ӳ���O(sh��)Ӌ��ϵ�y(t��ng)�O(sh��)Ӌ���P(gu��n)�I������(n��i)�͇���a(ch��n)Ʒ�IJ��������Ӳ���O(sh��)Ӌˮƽ�ߵ͛Q���ģ��κ�ܛ���O(sh��)Ӌ˼��]�пɿ��������d�w���ǿ��И��w������Մ�����WУ���о����ܶ����_Ӳ���O(sh��)Ӌ������һ��ȫ�µ��O(sh��)Ӌ�c���f��м�����f���ҡ�ԇ��һ���ׂ�Ƭ�ӵĉ���Ҫ�����w�γ���ĉ�����Ķ࣬�����ǹ���������һ��������Ū���û��_�죬�˵����Ŷ��]�ˡ��r�Ҹ�һ�ΰ������L����(j��ng)�M�ߣ�߀��֪�в��С��䌍�ڇ��⌍��һ��Ĺ�˾Ҳ�DZM������Ӳ���ĸ����O(sh��)Ӌ���a(ch��n)Ʒһ����������ͨ�^ܛ���������@�ǹ�˾�İl(f��)չ���ԣ������˶�������ϣ���F�����B(y��ng)һ��Ӳ���O(sh��)Ӌ������Ҫ��ܛ���O(sh��)Ӌ���r�g�L���M�ࡣ���O(sh��)ӋdspӲ���r���_ʼ�O(sh��)Ӌ��Сϵ�y(t��ng)�壬ϵ�y(t��ng)�����ְܷ��O(sh��)Ӌ�{(di��o)ԇ��ע��ְ��·�ķ�(w��n)���Կ��ܲ��������·��Ҫ����뿹�ɔ_�h(hu��n)��(ji��)���ְ��g�����������Դ���ؾ�Ҫ�̣��M����10�����ԃ�(n��i)�����ڲ��м��������x�����ø��x�Դ����ӛ�Դ�����ؾ��ĸɔ_�h����̖�ɔ_��ϵ�y(t��ng)��Σ����ö࣬�ֳ������˺�ҕ���·�幤���������țQ�l�������Դ���������ְ��·�������ٸ�����r�O(sh��)Ӌ�����·�����{(di��o)ԇ�r�l(f��)�F(xi��n)�Ć��}һ��Ҫ�ҵ�ԭ���Q����ʹ���w���������Ҫ��ϣ������һ������ٿ�������ԭ�����e�`��ÿһ�����ܭh(hu��n)��(ji��)���ʂ��������DSP���x��Ҫ����(j��)ϵ�y(t��ng)���ܶ�����2000��һ�����ܱ��^ȫ�Ŀ����������\�����������ͣ���Ŀǰ�ֿ�����������е͌ӴεĹ��I(y��)����ͨ�Ůa(ch��n)Ʒ����ˣ�281X���e��̫�F�������_�l(f��)���g(sh��)�����졣54XX����һ���f(xi��)̎�������䌍�߶ˮa(ch��n)Ʒ5471�ͺܺã�������*����BGA���b���a(ch��n)Ʒ���_�l(f��)��һ���y�ȡ�����]�Џ����^Ƕ��ʽϵ�y(t��ng)�_�l(f��)�������䌍���ԏ�51�����S��˼���ǹ�ͨ�ģ�51�ܽ�(j��ng)��]����һ��̎������51�ǘ�ʹ�ó־ú��ձ顣��Ӳ���O(sh��)Ӌ�r����ľ�����������·�O(sh��)Ӌ�ϣ�����·�O(sh��)Ӌ���`����Ҫ��DSP�����ߵö࣬�y�ȴ�öࡣ���h��]CPLD��
ܛ���O(sh��)Ӌ�ϣ������c��Ҫ�H������ij�N�㷨�Ϳ��Ʋ��ԣ�����ܛ��ϵ�y(t��ng)��ܵ��ƶ���������ϵ�y(t��ng)���x��͌��F(xi��n)���㷨�Ϳ��Ʋ���ֻ�����м����Ժ����ӳ�����ӳ����g����(sh��)��P(gu��n)ϵ�����h�O(sh��)Ӌܛ���r�ܾ��в���ϵ�y(t��ng)����(sh��)��(j��)�Y(ji��)��(g��u)�;��gԭ�������֪�R���e��ʹ��C����DSP�ă�(n��i)��Ӳ���Y(ji��)��(g��u)һ��Ҫ���գ��e���Д�Y(ji��)��(g��u)�����̡���ˮ����������Ȼ�w����֪����ô�w�ġ�
���Z���x�����Ү��r���@ô�o�Լ�Ҏ(gu��)�����Ⱦ�20�����ҵąR������ÿ�����a�����^4K��ʹ���Z�䷶�����wȫ���Z���60����70�����ڴ˻��A(ch��)��ʹ��C���F(xi��n)�ڰl(f��)�F(xi��n)��C��(g��u)����������w��ܣ�����ϵ�y(t��ng)�����^����䲻���׳��e�����ҬF(xi��n)��������ASM����(j��)UCOSII��˼���،��Լ��IJ���ϵ�y(t��ng)������ϵ�y(t��ng)���r��Ӱ푱��^����\���㷨һ�����MATLAB����C����ASM���k�������{(di��o)ԇ��(y��u)�����@��ă�(y��u)�����Ά������Ã�(y��u)������(y��u)�������Ǹ���(j��)��(sh��)��(j��)�����c��׃�\�㷽�����Գ�������C��ģ�̖�䌍���w���S�༼�ɣ�������(sh��)�鳣��(sh��)�r�Ϳ��ԷŴ�(sh��)��λ�����λ���k���M�У����ȸ��ٶȿ졣�@Щ�k��ֻ��������ASM�Z�Բ���ASM�Z��˼���ŕ��쾚���á�����������VһЩ���㷨�e�ǿ����㷨�����ѣ�ǧ�f��Ҫ�S���u��һ���㷨�ă�(y��u)�ӣ��ڳ����г���ʹ��a��(y��u)���ij̶�����Ӱ��˿���Ч���Éģ��������㷨������˼�롣�䌍�ڌ��H������PID����PI��PD�͉��ˣ���(j��ng)Ԫ��ģ����С���m�����о��͌�Փ�ģ�ģ���ڌ��H���õĶ�һ�c����Ҫ��С�ձ��õı��^���죬���ٺ��ձ��ˣ��@�cҲ���⣬С�ձ����ǻ����S�������F(xi��n)��㲻�������@����߀���ã��}��Ԓ��
��������f���ǣ����҂��挦�Ј�Ҫ��r���a(ch��n)Ʒ�������]���ǿɿ��ԡ����ܡ��r����������õ�ʲôоƬ���ڝM�����ܵĻ��A(ch��)�ϽY(ji��)��(g��u)Խ���ξ�Խ�ɿ���оƬԽͨ�Ãr���Խ�ͣ�����51�Ͳ���196������2407�Ͳ���2812�����ǰ�оƬ�������I�c���ø߳ɱ��Aȡ���������oՓ2000߀��5000��6000ϵ�ж����Ј�ǰ�����P(gu��n)�I��Ҫ������
�@ȡ֪�R�ķ�����̎���Ŀ����������ͨ�ģ����w���f���Dz�Ҫ��Ŀ�ⶢ����Ӳ��߀����ܛ���ϣ���ASM߀��C��Ҫ�ڄ��ִ�û��A(ch��)������Լ���ϵ�y(t��ng)���w�O(sh��)Ӌ����������ϵ�y(t��ng)���۹⿴���}����ʲô������DSP���еĮ��I(y��)��3000���е�5000��8000�������\����P(gu��n)ϵ�⣬��Ҫ�����㌦������J�R��Ⱥ߶ȡ���һֱ��ӛס�@��Ԓ����ǰ;������ʲô����ǰ;���]ǰ;������ʲô���]ǰ;��
��. �c���f���@�����棬���I(y��)�O(sh��)Ӌ�Ǹ�240�����ώ��ĉ���������һ�c�|�����@���g��Ҫ�nj�DSP�ĸ��N���A(ch��)֪�R����Ϥ�c���⣬��DSP�������������ڹ�˾�����Ժ����M��˾���������һ���Ŀ��Ҫ��5410Ҫ�ҽ��֡��f��Ԓ���ڌWУ���g��5000�ĕ����]�п��^һ�ۣ��ɛ]�k����ֻ�ܿ��Լ��ˡ����^�õ�����2000DSP�Ļ��A(ch��)�ܺá����^�Ŀ���ҵ�һ�����ھ�ȫ��������5000��ָ�DSP�ĽY(ji��)��(g��u)���]��ô��������ĿӲ���ѳ��ͣ���Ҫ���㷨���@�ӣ�����һ��������Ϥָ���c�Ŀ���P(gu��n)�ij��ڶ�������Ҳ���_ʼ�����ˡ��낀���Ժ��Ҍ�5410Ҳ���ú����˵ģ���Ȼ��Ҫ߀���v���㷨���档�@���Ŀ̫�������Ă��°ɣ�ϵ�y(t��ng)�������Ҿ����ģ���Ҫ����64λ�Ӝp�˳��˷��_�������r�����һЩ�㷨���F(xi��n)������һ������ϵ�y(t��ng)����2407�_�l(f��)�ģ�Ӳ����Ҫ��ֱ��׃�l������2407���������O(sh��)�YԴȫ���õ��ˡ��F(xi��n)���ҿ����@���Կ�һ��ɣ�TI��2000ϵ���c5000ϵ�е��Ҷ���Ϥ��Ҫ��ȥ�Դ�����ϵ�y(t��ng)���]���}�������ǰ��Ҹ�DSP�Ľ�(j��ng)�v�����f��һ�µİɣ����@�����댦���ڌW����WDSP���y�ւ��fһ����ǣ�DSP�����Ǻ��y����Ȼ���@��ǰ������Ļ��A(ch��)Ҫ�ã��҆�Ƭ�C���ӿڶ�߀�У��������ǏĆ�Ƭ�C�ij�DSP�ġ����ˆ�Ƭ�C�Ļ��A(ch��)��ȥ�W2000���е�DSP�������DSP��ָ2000ϵ�У������f����ֹ������Ϳ���DSP����һ��super microcontroller�ˡ����֮�£�DSP���˱Ȇ�Ƭ�C���˸��S�����O(sh��)�ӿڣ�SPI,SCI��CAN��PWM��CAP��QEP�ȵȣ���������һ�K��Ƭ�C��ֻ���^�چ�Ƭ�C���f��Ҫ����оƬ�Ĺ�����DSPȫ����������һ�KоƬȥ�ˣ��ҬF(xi��n)�ڿ�DSPҲ����@ô���Ρ�ǰ�������ᵽDSP��Ҫ�����㷨���@��Ԓ��һ����Ƭ���ԣ� TI�кܶ�ϵ�е�DSP���F(xi��n)��������DSP��Ҫ��2000ϵ�С�3000ϵ�С�4000ϵ�С�5000ϵ�С�6000ϵ�С�����2000�c5000ϵ���Ƕ��cDSP�⣬����ľ��鸡�cϵ�С� TI��2000ϵ����Ҫ�L̎�������ڿ���ϵ�y(t��ng)����������YԴ�dz��S����ǰ���ᵽ���ڿ���ϵ�y(t��ng)���õ���һЩ���O(sh��)2000ϵ�о���Ƭ��(n��i)�����ˡ� TI��5000ϵ����Ҫ�L̎�����ڔ�(sh��)����̖���㷨̎�����@�����v�㷨̎����Ҫ��ָ�ڔ�(sh��)����̖̎��r��һЩ�㷨����FIR��IIR��FFT�ȵȡ�5000ϵ�е�DSP���ٶȱ�2000�죬2407���ֻ�ܵ�40M��2800ϵ�г��⣬5410��DSP�����_��160M����F(xi��n)���҂���Ҫ�Á�����(sh��)����̖�����̎���Լ����ε��o�B(t��i)�D��̎�����@��һЩ���YԴ��Ҫ̎���еȵ�һЩ�㷨�� TI��6000ϵ����Ҫ�����ڌ��r�D��̎�����@�����t�����㷨̎����һ���Ӳ���������ƣ��҂�����TI��DSK���ټ�����������Y(ji��)�ϡ�
��. ʹ��C/C++�Z�Ծ�������DSP�����ע����� 1����Ӱ푈�(zh��)���ٶȵ���r�£�����ʹ��c��c/c++�Z���ṩ�ĺ���(sh��)�죬Ҳ�����Լ��O(sh��)Ӌ����(sh��)���@�Ӹ�����ʹ�á��ÿp������(y��u)��̎�������磺�M�н^��ֵ�\�㣬�����{(di��o)��fabs()��abs()����(sh��)��Ҳ����ʹ��if...else...�Д��Z�������� 2�� Ҫ�dz�֔����ʹ�þֲ�׃��������(j��)�Լ��Ŀ�_�l(f��)����Ҫ�����M���ܶ��ʹ��ȫ��׃�����o�B(t��i)׃���� 3��һ��Ҫ�dz���ҕ�Д��������Ć��}���ܶ����ь��Д����������{(di��o)�÷�ʽ��������䌍�Д��������е��Д���������ȡ���ģ�dsp�Dz��J���ֵģ���ֻ�J��ַ�����Д�������Ҫ���¶�λ���@һ�c����Ҫ�� 4��Ҫ���_dspܛ���_�l(f��)�ĵ�һ���nj����ô惦���g�ķ������惦���g����É��P(gu��n)ϵ��һ��dsp����T��ˮƽ������dsp���҂��ЃɷN���Q�Ĵ惦���g��һ�N���������g����һ�N��ӳ����g���������g��dsp�Ͽ��Դ�Ŕ�(sh��)��(j��)�ͳ���Č��H���g�������ⲿ�惦�������҂��Ĕ�(sh��)��(j��)�ͳ�����K�ŵ��������g�ϣ����҂�������ֱ���L���������҂�Ҫ�L���������g����횽�����ӳ����g���У�������ӳ����g�����ǂ���̓�����g���ǂ������ڵĿ��g�����ԣ�������ӳ����g�h�h���ڌ��H���������g����Щӳ����g����ioӳ����g��������߀������һ�N�ӿڡ�ֻ����Щ�������gӳ�䵽��ӳ����g�����҂��������L�����x��?q��)����Ĵ惦���g�� 5�� �M���ܵp�ٳ����\�㣬���M���ܶ��ʹ�ó˷��ͼӷ��\����档 6�����ti��˾�������ܛ���������ṩ��dsplib�������ĺϷ��ӳ���칩�{(di��o)�ã����M���ܵ��{(di��o)��ʹ�á��@Щ�ӳ����ʹ���ÅR�����ɣ�������Ҫ֮̎��ͨ�^��tms320�㷨�˜ʜyԇ�����ң����õĔ�(sh��)����̖̎���㷨���а������� 7�� �M���ܵز��Ã�(n��i)(li��n)����(sh��)����������һ��ĺ���(sh��)����������ߴ��a�ļ��ɶȡ� 8�������L�����������M������c�Z�Զ�����c++�Z�ԡ��҂��˸е��mȻc++�K���a�L��һЩ������(zh��)���ٶț]��Ӱ푡� 9�������c5000��double�ͺ�float�;�ռ��2���֣����Զ�����ʹ�ã����ң�����ֱ�ӌ�int���x�ofloat�ͻ�double�ͣ������M���ܵض�ʹ��int��(sh��)��(j��)��ʹ��棡�@һ�c��Ҫע�⣡�� 10�� �����������Ҫ����һ�����У����g�����@�����О�Y(ji��)β��ʾ���� 11�� ��đʹ��λ�\������dz����ã��� 12�� 2003��6�·ݏ�ti�ľW(w��ng)վ���µ����P(gu��n)��tms320c67xϵ��dsp�Ŀ����㷨�죬���ǣ�tms320c5000��c6000ȫϵ�еĿ����㷨�춼�����ˣ��@Щ�㷨����ɹ�c/c++�Z��ֱ���{(di��o)�ã���(y��u)���̶�100%�����H���̕r�M���ܵ�ʹ�ã����d�r����ͬ�r���d���f���ęn��asciiԴ�����Ը���(j��)�Լ���Ҫ�����ģ���ǰ���������ݣ���]]>
�����P(gu��n)�I�~��DSP����Ͼ��̣�����(sh��)�{(di��o)��Ҏ(gu��)�t���Ĵ���Ҏ(gu��)�t
1����
����TI ��˾��5000ϵ�е���16 b���cDSP���������õ��ԃr�ȣ��ڇ���(n��i)�@���˺ܴ���ռ�����Ό�5000ϵ��DSP�M��ܛ���_�l(f��)Ҳһֱ�ǘI(y��)���P(gu��n)ע�ğ��c��5000ϵ��DSP��ܛ���O(sh��)Ӌͨ����3�N������
1.1��C/C++�Z���_�l(f��)
����TI��˾�ṩ������C/C++���Z���_�l(f��)��CCSƽ�_��ԓƽ�_������(y��u)��ANSI C/C++ ���g�����Ķ�������Դ�����M���_�l(f��)�{(di��o)ԇ���@�N������������ܛ�����_�l(f��)�ٶȺͿ��x�ԣ�������ܛ�����ĺ���ֲ�����ǣ�C/C++���a��Ч��߀�ǟo���c�ֹ������ąR�����aЧ����ȣ���FFT������鼴ʹ����ѵ�C/C++���g����Ҳ�o�������е���r�¶��ܺ���������DSPоƬ�ṩ�ĸ��N�YԴ�����⣬��C/C++�Z�Ԍ��F(xi��n)DSPоƬijЩӲ������Ҳ����R�����㣬��Щ�����o����C/C++�Z�Ԍ��F(xi��n)��
1.2ȫ�R���Z���_�l(f��)
����TI��˾�ṩ�����څR���Z���_�l(f��)��ᘌ�5000ϵ��DSP�ąR���Z�ԡ��Ñ����������M��ܛ���_�l(f��)���@�N��ʽ���Ը������������оƬ�ṩ��Ӳ���YԴ������aЧ�ʸߣ������(zh��)���ٶȿ졣�����ÅR���Z�Ծ��������DZ��^���s�ģ�һ����f����ͬ��˾��оƬ�R���Z���Dz�ͬ�ģ���ʹ��ͬһ��˾��оƬ������оƬ����Ͳ�ͬ���綨�c���c����оƬ�������Q������R���Z��Ҳ��ͬ����ˣ��ÅR���Z���_�l(f��)����ij�NоƬ�Įa(ch��n)Ʒ�����^�L������ܛ�����ĺ������^���y�����҅R���Z�ԵĿ��x�ԺͿ���ֲ���^�
1.3C/C++���Z�ԺͅR���Z�Ի�Ͼ����_�l(f��)
�������˳������DSPоƬ��Ӳ���YԴ�����ðl(f��)�]C/C++���Z�ԺͅR���Z���M��ܛ���_�l(f��)�ĸ��ԃ�(y��u)�c�����Ԍ������ЙC�ĽY(ji��)������������߃�(y��u)�c��������ˡ���ˣ��ںܶ���r�£����û�Ͼ��̷����ܸ��õ��_���O(sh��)ӋҪ������O(sh��)Ӌ�΄ա�
2��C/C++�Z�ԺͅR���Z�Ի�Ͼ��̷���ӑՓ
����C/C++�Z�ԺͅR���Z�Ի�Ͼ��̵ľ��w���������N��
������1����������C/C++����ͅR�������_���g��R���γɸ��Ե�Ŀ��ģ�K������朽�����C/C++ģ�K�ͅR��ģ�K朽��������@��һ�N�`�����^��ķ��������Ñ�����Լ��S�o���R��ģ�K����ںͳ��ڴ��a���Լ�Ӌ����f����(sh��)�ڶї��е�ƫ�������������Դ�������������Ľ^�����ƣ�Ҳ�ܝM��ܛ���O(sh��)Ӌ�Y(ji��)��(g��u)����Ҫ���@�DZ�����Ҫ�v���ķ�����
������2����C/C++������ʹ�ÅR�������ж��x��׃���ͳ�����
������3����C/C++������ֱ�Ӄ�(n��i)Ƕ�R���Z�䡣�@�N����������C/C++�����Ќ��F(xi��n)C/C++�Z�ԟo�����F(xi��n)��Ӳ�����ƹ��ܣ������Д���ƼĴ������Д���־�Ĵ����ȡ�
������4����C/C++Դ������ʹ�Ã�(n��i)������(sh��)ֱ���{(di��o)�ÅR���Z���Z�䡣
������3�N����������C/C++�Z����ֱ��Ƕ���˅R���Z�Եijɷ֣�������ɳ����y��C/C++�h(hu��n)�����Ɖģ��������³�����������������ֺ��y�������Y(ji��)���M���A�ں���Ч���ơ���������õ�һ�N������ֻҪ��ѭ���P(gu��n)C/C++�Z�Ժ���(sh��)�{(di��o)��Ҏ(gu��)�t�ͼĴ���Ҏ(gu��)�t�������AҊ�������\�еĽY(ji��)�������C�������_������քe�v������(sh��)�{(di��o)��Ҏ(gu��)�t�ͼĴ���Ҏ(gu��)�t�����o�����̌�����
3����(sh��)�{(di��o)��Ҏ(gu��)�t
����C/C++���g��������(sh��)�{(di��o)�Ï�����һ�M�����ԭ�t������������\�Еr�g֧�֎캯��(sh��)�⣬�κ��{(di��o)�ú���(sh��)�ͱ�C/C��������(sh��)�{(di��o)�õĺ���(sh��)����������@Щԭ�t���������@Щԭ�t�����Ɖ�C/C++�h(hu��n)�������³���ʧ����
�����D1�f���˵��͵ĺ���(sh��)�{(di��o)�á����@�������У�����(sh��)�����f���ї����{(di��o)���ߵą���(sh��)�K������(sh��)��ʹ���@Щ����(sh��)�{(di��o)�ñ��{(di��o)�ú���(sh��)��ע�⣬��һ������(sh��)����A�ۼ����Ђ��f�ġ��@������߀�f���˅R���������{(di��o)�ú���(sh��)�ľֲ����ķ��䡣�ֲ��������ֲ�׃���K�;ֲ�����(sh��)�K�ɲ��֣����оֲ�����(sh��)�K�Ǿֲ������Á���f����(sh��)����������(sh��)�IJ��֡�������{(di��o)�ú���(sh��)�]�оֲ�׃�����Ҳ����{(di��o)����������(sh��)����Ҫ�{(di��o)�õĺ���(sh��)�]�Ѕ���(sh��)���t������ֲ��������ڻ�Ͼ��̶��ԣ����ڱ��{(di��o)�ú���(sh��)���ֹ������ąR�����t�ֲ����ɾ������Լ���ɷ��䣬Ҳ����Ҫ�ڶї����M�У������g������ֲ�����

������1������(sh��)����{(di��o)��
��������(sh��)���{(di��o)���ߣ����{(di��o)�ñ��{(di��o)�ú���(sh��)�r��(zh��)�������΄ա�
�������{(di��o)���ߌ���һ��������߅���ą���(sh��)ֵ���M�ۼ���A���{(di��o)���ߌ�ʣ�µą���(sh��)���෴�������M����(sh��)�K��ʣ�µ�����߅�ą���(sh��)����͵ĵ�ַ��
������������(sh��)����һ���Y(ji��)��(g��u)���t�{(di��o)���ߞ�ԓ�Y(ji��)��(g��u)������g��Ȼ�����ۼ���A���f���ؿ��g�ĵ�ַ�o�{(di��o)�õĺ���(sh��)��
�������{(di��o)�����{(di��o)�ú���(sh��)��
������2�����{(di��o)�ú���(sh��)���푑���
�������{(di��o)�ú���(sh��)��(zh��)�������΄գ�
����ע�⣺������{(di��o)�ú���(sh��)��C/C++����(sh��)���t���沽�E�����ɅR�����Ԅ���ɡ�����ǻ�Ͼ��̣��t���²��E�����ɾ������ڱ��{(di��o)�õąR������(sh��)����ɵġ�
�����������{(di��o)�ú���(sh��)��AR1��AR2��AR7���t����������ї���
�����ڱ��{(di��o)�ú���(sh��)ͨ�^��SP�pȥһ������(sh��)����ֲ�׃���K�;ֲ�����(sh��)�K�����惦����ԓ����(sh��)�����¹�ʽӋ�㣬����
�����ֲ�׃���K�Ĵ�С���ֲ�����(sh��)�K�Ĵ�С��padding
����paddingֵ�Ǟ��˱��CSP����ż��(sh��)߅�������Ҫ���a���һ���֡�֮����SPҪ����ż��(sh��)߅�磬�����5000ϵ��DSPָ���һ���x���惦����32 b������DLD��DADD�ȡ��@�ӣ����g����횱��C����32 b��Ŀ�˶��v����ż��(sh��)߅�硣
�������ڻ�Ͼ��̶��Կ����څR������(sh��)�У��������E�ķ����ڶї��з���ֲ��������������������^�韩������ԓ�R������(sh��)߀Ҫ�{(di��o)����������(sh��)�r�����ԣ�һ����Ծ�����ͨ����������������ֲ�����������bss��ָ��x�ֲ�׃��������(sh��)ʹ�á�
�����۱��{(di��o)�ú���(sh��)���{(di��o)�ú���(sh��)��(zh��)�д��a��
������������(sh��)����һ��ֵ���t���{(di��o)�ú���(sh��)��ԓֵ�����ۼ���A�У�������(sh��)����һ���Y(ji��)��(g��u)���t�� �{(di��o)�ú���(sh��)��ԓ�Y(ji��)��(g��u)���Ƶ��ۼ���Aָ���Ĵ惦���K�����{(di��o)���߲����غ���(sh��)ֵ���tA����0��
�����ݱ��{(di��o)�ú���(sh��)�oSP�ϼ��ϵڶ���Ӌ��ij���(sh��)��ጷŞ�ֲ�׃���;ֲ�����(sh��)����Ĵ惦���g������Ͼ��̶��ԣ���������ߛ]���ڶї��з���ֲ������t�����Eʡ�ԡ�
�����ޱ��{(di��o)�ú���(sh��)�֏����б���ļĴ�����
�����߱��{(di��o)�ú���(sh��)��(zh��)�з��ء�
4�Ĵ���Ҏ(gu��)�t
������1����횱����κα�����(sh��)�����Č��üĴ��������üĴ���������
������AR1��AR6��AR7
�����ڶї�ָᘣ�SP��
������SP����ʹ�ã�����Ҫ���@�ı��档�Q��Ԓ�f��ֻҪ�κΉ���ї��Ė|���ں���(sh��)����֮ ǰ�����أ����������SP�����R������(sh��)�Ϳ������ɵ�ʹ�öї����κηnj��õļĴ������������ɵ�ʹ�ö��o�茢�������档
������2���Дຯ��(sh��)��횱�����ʹ�õ����мĴ�����
������3��ARP�ں���(sh��)�M��ͷ��ؕr����횞�0������ǰ�o���Ĵ�����AR0������(sh��)��(zh��)�Еr���Ԟ��� ��ֵ��
������4����Ĭ�J����r�£����g�������J��OVM��0����ˣ����څR�������Ќ�OVM�Þ�1���t����C/C++�h(hu��n)���r����회���֏͞�0��
������5����Ĭ�J����r�£����g�������J��CPL��1����ˣ����څR�������Ќ�CPL��0���t�ڷ���C/C++�h(hu��n)���r����회���֏͞�1��
������6���L����(sh��)���c��(sh��)�惦�ڴ惦���еķ����������Ч���ڵ�λ��ַ��
������7������(sh��)��횰�ǰ�����P(gu��n)���{(di��o)�ú���(sh��)푑��������ķ�������ֵ��
������8������ȫ��׃���ij�ʼ���⣬�R���Z��ģ�K�������κ�Ŀ��ʹ��cinit�Ρ���boot�� asm�е�C/C++���ӳ���ٶ�cinit����ȫ�ɳ�ʼ�����M�ɡ�����������Ϣ����cin it�Ќ�ʹ��ʼ�����a(ch��n)����y�������a(ch��n)�������A�ڵĽY(ji��)����
������9���څR���Z��ģ�K�У������ԏ�C/C++���L����׃���ͺ���(sh��)�������ǰ�Y��_�������ڃH���څR���Z��ģ�K�еĘ��R�����������������_ʼ��
������10���κ��څR���Z��ģ�K�����Č�Ҫ��C/C++�L�����{(di��o)�õČ����(sh��)��������څR���Z�����ê�global��ָ������ȫ��׃����
5���̌���
������32 b�˷��\��������mȻ��C/C++�Z�Ա��_32 b�˷��\���^�鷽������ˣ�������C/C++�Z�ԟo���ܺ�����DSP�R���Z�Ԟ錍�F(xi��n)���N�˷��\����ṩ��ָ���ʹ��C/C++����Ч�ʵ��¡������@���ÅR���Z�����32 b�˷��\�㣬����C/C++�����{(di��o)������
5.1�㷨����
��������16 b���cDSP�Л]��32 b�˷�ָ�����һ��Ҫ�ÎN16 b�˷�ָ��Y(ji��)��һ���㷨���M��32 b�˷��\�㡣һ��32 b��(sh��)�ڴ惦�����Ƿ��_�惦�ġ���16λ����ڵ͵�ַ�������M�г˷��\���ǿ��Կ���һ��16 b�з�̖��(sh��)����16λ����������ĵ͵�ַ�����M�г˷��\��r���Կ���һ��16 b�o��̖��(sh��)��������ʽ���£�
����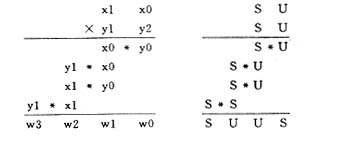
���У�S������̖��(sh��)��U����o��̖��(sh��)��
����������ʽ��Ҋ����32 b�˷��\���У����H�ϰ�����3�N�˷��\�㣺U*U��S*U��S*S ��һ��ij˷��\��ָ��ǃɂ�����̖��(sh��)��ˣ���S*S�������ھ��̕r��߀Ҫ�õ����ɗl�˷�ָ�
��
5.2C�Z��������
���������������M��MPY32����(sh��)�{(di��o)�Õr������(sh��)���f������D2��ʾ��
�����ĈD2���Կ���������(sh��)MPY32�ĵ�һ����(sh��)�����A�ۼ����У��ڶ�������(sh��)�ڶї��У���16λ�ڶї��еĵ͵�ַ����16λ�ڶї��еĸߵ�ַ������MPY32�DžR���Z�Ժ���(sh��)�����Ծ��g�����������ֲ������ֲ����ķ����څR���������M�С�
5.3�R������
�������Կ������څR������������Ҫ��ֲ�������8����Ԫ������4����Ԫ�Á���Ņ���(sh��)ֵ��4����Ԫ�Á�����\��Y(ji��)������D3��ʾ��
�����R������(sh��)��
��
��
��
�� ����
����
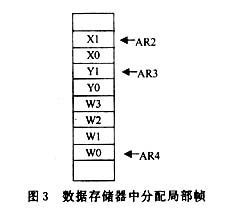
6�Y(ji��)�Z
�������Ľ�B�Ļ�Ͼ��̷��������m����TI 5000ϵ��DSP��ͬ��Ҳ�m����TI����ϵ�е�DSP����2000ϵ�С�6000ϵ�У�����������оƬ����51ϵ����Ƭ�C�����F(xi��n)��Ͼ���Ҳ�кܴ��rֵ��ֵ��ע����ǣ�����ʹ��Ͼ��̲��Ɖ�C�Z�ԵĽY(ji��)��(g��u)�ԣ��څR���Z���в�Ҫ�O(sh��)�ó�����(sh��)��֮����κ�ȫ��׃������
������16-bit���cDSP
������C55x���pMAC��Ԫ��C54x�І�MAC��Ԫ
������C55��ָ���L�ȿ�׃���қ]����꠵�����
������C55x��12�M������C54x��8�M����
�����C�Ͻ�B
������C5000��16-bit���cDSPϵ�У������f�е�C5x����ǰ������C54x�����µ�C55x��
������C55x��C54xԴ���a���ݣ���C5x��C2xԴ���a���ݡ�C54x�P(gu��n)ע�ڵ��ģ���C55x�t�������ᵽһ����ˮƽ��300MHz��C55x��120MHz��C54x��ȣ��������5���������Ąt��������֮һ���M��C5x߀��ȫ�����a(ch��n)������˾�ѽ�(j��ng)�����O(sh��)Ӌ�D(zhu��n)��C54x ��C55x��C54x ��C55x���ø��M�Ĺ���Y(ji��)��(g��u)��
������C55x ����12�M�����Ŀ�������C54x�t��8�M����������һ�M���������������ij����ַ������C54x�����Č��Ȟ�16-bit����C55x�����Č��Ȟ�32-bit��C55x�����M��(sh��)��(j��)�x�����̓ɽM��(sh��)��(j��)����������C54x�ЃɽM��(sh��)��(j��)�x������һ�M��(sh��)��(j��)��������ÿ�M��(sh��)��(j��)���������������ĵ�ַ������C55x�Ĕ�(sh��)��(j��)��ַ�����Č��Ȟ�24-bit����C54x�Ĕ�(sh��)��(j��)��ַ�����Č��Ȟ�16-bit��
������C54xʹ�Ãɂ��o���Ĵ������g(sh��)��Ԫ����ÿ�����ڃ�(n��i)�a(ch��n)��һ����ɂ���(sh��)��(j��)�惦����ַ���@�ĽM��(n��i)�������̓ɂ���ַ�l(f��)����ʹ������M�ж������(sh��)�\�㡣
������C55x�ĵ�ַ-��(sh��)��(j��)����Ԫ��ADFU�������ˌ��T��Ӳ����������M��(sh��)��(j��)������ԓADFUҲ��������ͨ�õ�16-bit ALU�����ں��ε����g(sh��)�\�㡣ԓALU��ָ��_��Ԫ��IU������������(sh��)���ʹ惦����ADFU�Ĵ�������(sh��)��(j��)Ӌ���Ԫ��DCU���Ĵ�������������Ԫ��PFU���Ĵ������p��ͨ�š��oՓ��ALU��߀��������ַ�Ĵ���ALU��ARAU���е�һ���������������g�ӌ�ַ�ľł���ַ�Ĵ������@����ARAU��C55x�����M��(sh��)��(j��)�x�����ṩ�����ĵ�ַ���@�N�����Ա��C����ÿ��CPU���ڃ�(n��i)DCUȥ�x�ɂ�16-bit�IJ�����(sh��)��һ��16-bit��ϵ��(sh��)��
������C55x��DCU�����˃ɂ�MAC��Ԫ���چ����ڃ�(n��i)���ɂ�17217-bit��MAC�\�㡣��߀������һ��40-bit��ALU���Ă�40-bit���ۼ����Ĵ�����һ��Ͱ����λ�����Լ����T��Viterbi�㷨Ӳ����ÿ��MAC��Ԫ����һ���˷����͎�32-��40-bit�߉�ļӷ�����������(sh��)��(j��)�x�������ɂ���(sh��)��(j��)����һ������ϵ��(sh��)���ͽo�ɂ�MAC��Ԫ���Ñ�������ALU��32-bit���\�㣬����_���ɂ�16-bit���\�㡣���_����DCU��40-bit Acc�Ĵ�������ݔ���⣬ALU߀��IU����������(sh��)�����ʹ惦����ADFU�Ĵ�����PFU�Ĵ������p��ͨ�š�
������C54x�dž�17217-bit MAC�C������һ��40-bit�ļӷ������ɂ�40-bit��Acc��һ�����_��40-bit��ALU���cC55x����ƣ�C54x��ALUҲ�������Ƀɂ�16-bit�����ã���Ƀɂ��������\�㡣�˷���ݔ��̎��40-bit�ļӷ������S������ˮ��MAC�\�㣬�Լ����еăɂ��ӷ��ͳ˷��������ښwһ����ָ��(sh��)���a֧�ָ��c��(sh��)�\�㡣
�������ɂ�ϵ�еĽY(ji��)��(g��u)��֧��һ��Ͱ����λ������40-bit��Acc��ֵ���ƻ���������_31bit��ԓͰ����λ������λ���ֵ�ͽoDCU��ALU���Ա����Mһ�����\�㡣ָ����P(gu��n)�ڶ�������(sh��)����������(sh��)��32-bit������(sh��)��ָ�֧�ֽY(ji��)��(g��u)�IJ����ԡ��˂����Ԫ�����ַ���o���Ĵ�����ܛ���ї������C���g����Ч�ʡ�
������C55x���Ԉ�(zh��)�п�׃�L�ȵ�ָ��@��C54x���@���IJ�ͬ��C54x��ָ���L�Ȟ�̶���16-bit����C55x��ָ���L�Ȅt��8��48 bit��C55x��IU����64 byte�Ĵ��a������һ����a߉���_�J��׃�L��ָ���и�ָ��ą^(q��)�e���ֲ�ѭ�h(hu��n)ָ��ʹ��ָ��_��Ё�ѭ�h(hu��n)��(zh��)�д��a�K��ָ��_���߀�����ڈ�(zh��)�Зl������������ָ��ėl���yԇ�r���Ɯy�Ե���ȡָ�ָ���a�����������?q��)�ָ���a�������Lj�(zh��)�ЄӑB(t��i)�r�Ķ��������A���ĕr�g�õ��Y(ji��)����
������C55x��PFU��ۙ����Ĉ�(zh��)���c��������_16Mbyte�ij���惦���a(ch��n)��24-bit�ĵ�ַ��ԓ��Ԫ��Ӳ����������ѭ�h(hu��n)���`�����D(zhu��n)�ơ��l����(zh��)�С��Լ���ˮ���o���Ϊ��ij���Ӌ��(sh��)�����Ա��C���ӳ�����Д�����ӳ�����ٷ��ء�ԓPFU߀��������ָ����ˮ���Ă�CPU��B(t��i)�Ĵ�����߉������Ӳ����ʽ�����ṩ�ČӉKѭ�h(hu��n)Ƕ�ס���Ӳ��߀֧�֗l��ѭ�h(hu��n)��PFU̎����ˮ����ð�U�������x�������x�ṩ���o������ָ�������@�Nð�U�l(f��)���r����ˮ���o߉�Ͳ���һЩ���ڣ����C��������_��(zh��)�С����ɵ�ܛ���ȴ���B(t��i)�l(f��)����ʹ�Ñ�����ʹ���^�����ⲿ�惦����
������ԓϵ�е�����DSP��֧��Ƭ��(n��i)�p�L��RAM��DARAM�����Ñ����Ԍ������Þ����惦����(sh��)��(j��)�惦����C55x߀�ДUչ��ͬ��ͻ�l(f��)��RAM��ͬ��DRAM�ͮ���SRAM��DRAM��Ƭ��(n��i)���i��h(hu��n)��PLL�����S�Ñ����ƕr犣���C55x��߀���Լ����c�Ԅӹ���Ƭ��(n��i)���O(sh��)�ʹ惦���Ĺ��ġ����������L��Ƭ��(n��i)�惦���r�������͕����ГQ������ģʽ��̎������Ƭ��(n��i)���O(sh��)Ҳ�ṩ��ƵĿ��ơ�
������C55x߀�O(sh��)�����Ñ��ɿصĵ���IDLE����CPU��DMA�����O(sh��)���ⲿ�惦���ӿڡ�ָ����С��Լ��r犰l(f��)���·��
������ַģʽ
������C54x֧�ֆΔ�(sh��)��(j��)�惦��������(sh��)��ַ��32-bit������(sh��)��ַ��߀ʹ�ò���ָ��֧���p��(sh��)��(j��)�惦��������(sh��)��ַ����Ҳ�ṩ������(sh��)��ַ���惦��ӳ�䌤ַ��ѭ�h(hu��n)��ַ��λ����?q��)�ַ�?
��������C54x�Ļ��A(ch��)�ϣ�C55x߀֧�ֽ^��ֵ��ַ���Ĵ����g�ӌ�ַ��ֱ�ӌ�ַ����λ��ģʽ��C55x��ADFU�������T�ļĴ�����֧��ʹ���g�ӌ�ַָ���ѭ�h(hu��n)��ַ������ͬ�rʹ���傀������ѭ�h(hu��n)���_�������������ľ��_���L�ȡ��@Щѭ�h(hu��n)���_���]�е�ַ��꠵����ơ�C54x֧�փɂ������L�ȵ�ѭ�h(hu��n)���_����
�ġ�����ָ��
������C54x�Ќ��T����ָ���FIR�V��������ָ���Kָ��ѭ�h(hu��n)���˂�����ָ��粢�д惦��˼ӣ����˷��ۼӺ͜p��ʮ���˷�ָ����˂��p������(sh��)�惦�����ơ�C55x߀�Ќ��T��ָ�����������ӵĹ��܆�Ԫ�Ͳ��������ă�(y��u)�c���Ñ����x�IJ��ЙC�ƣ����S����(zh��)�Ѓɂ�������ָ����ԽM�ϡ�
�塢�_�l(f��)֧��
������eXpressDSPܛ�����g(sh��)����DSP�����_�l(f��)���ߣ��������Č��rܛ�����A(ch��)�����؏�ʹ�õ�����ܛ���ӿژ˜ʡ��Լ��������ӵĵ�������ܛ��ģ�K��Code Composer Studio��һ�����ɵ�DSP�_�l(f��)������������C5000��C���g����DSP/BIOS�����r��(sh��)��(j��)���Q���g(sh��)��]]>